9 min
Scaling Security in the Age of AI: How TRM Labs Built Self-Improving Vulnerability Agents with Reinforcement Learning
TRM built the Codex Vulnerability Agent — an AI system that uses reinforcement learning to autonomously generate production-ready PRs across 150+ repos, addressing 100+ critical vulnerabilities a month without manual remediation
At TRM Labs, we're on a mission to build a safer financial future and protect the ecosystem from AI-enabled crime. Each day, we process petabytes of blockchain data across 45+ blockchains. As our engineering organization has continued to scale to support this mission, managing security vulnerabilities across our 150+ repositories has become a priority to both maintain our velocity and shore up our security posture.
Traditional vulnerability management has typically required manual intervention for each CVE: engineers had to analyze the vulnerability, understand the fix, update dependencies, test changes, and create pull requests. But our security team typically identifies more than 100 critical vulnerabilities each month as of Q2 2025 across diverse technology stacks (including Go, Node.js, Python, Rust) — making it clear to us that this manual process was unsustainable.
This challenge led us to build the Codex Vulnerability Agent — an AI-powered system that autonomously processes vulnerability reports from our security tools, generates fixes using OpenAI's Codex-RS, and creates production-ready pull requests with zero human intervention.
In this post, we'll share:
- Why we built an AI-first approach to vulnerability management
- How we architected a production-grade autonomous agent using Codex-RS
- Our implementation of reinforcement learning to continuously improve fix quality
The challenge: Vulnerability management at scale
Scale and complexity
- 150+ repositories across multiple technology stacks
- 100+ critical vulnerabilities identified monthly by security scanning tools
- Multiple package managers:
npm,pip,go.mod,Cargo.tomlandMaven - Diverse deployment patterns: microservices, data pipelines, ML models
Traditional pain points
- Manual effort: Each vulnerability required 30-60 minutes of developer time
- Context switching: Engineers pulled away from feature development
- Inconsistent fixes: Different approaches to similar vulnerabilities
- Misaligned prioritization: Limited clarity on exploitability meant critical, applicable vulnerabilities could be overlooked
Compliance requirements
- FedRamp High compliance, requiring rapid vulnerability remediation
- SOC 2 Type II audit trail for all security fixes
- Mean time to remediation (MTTR) targets under 72 hours for critical vulnerabilities
The traditional, manual approach simply couldn't scale with our growth and security requirements.
Architecture: Building an autonomous Vulnerability Agent
Our Codex Vulnerability Agent uses a three-stage pipeline designed for reliability, observability, and continuous improvement:
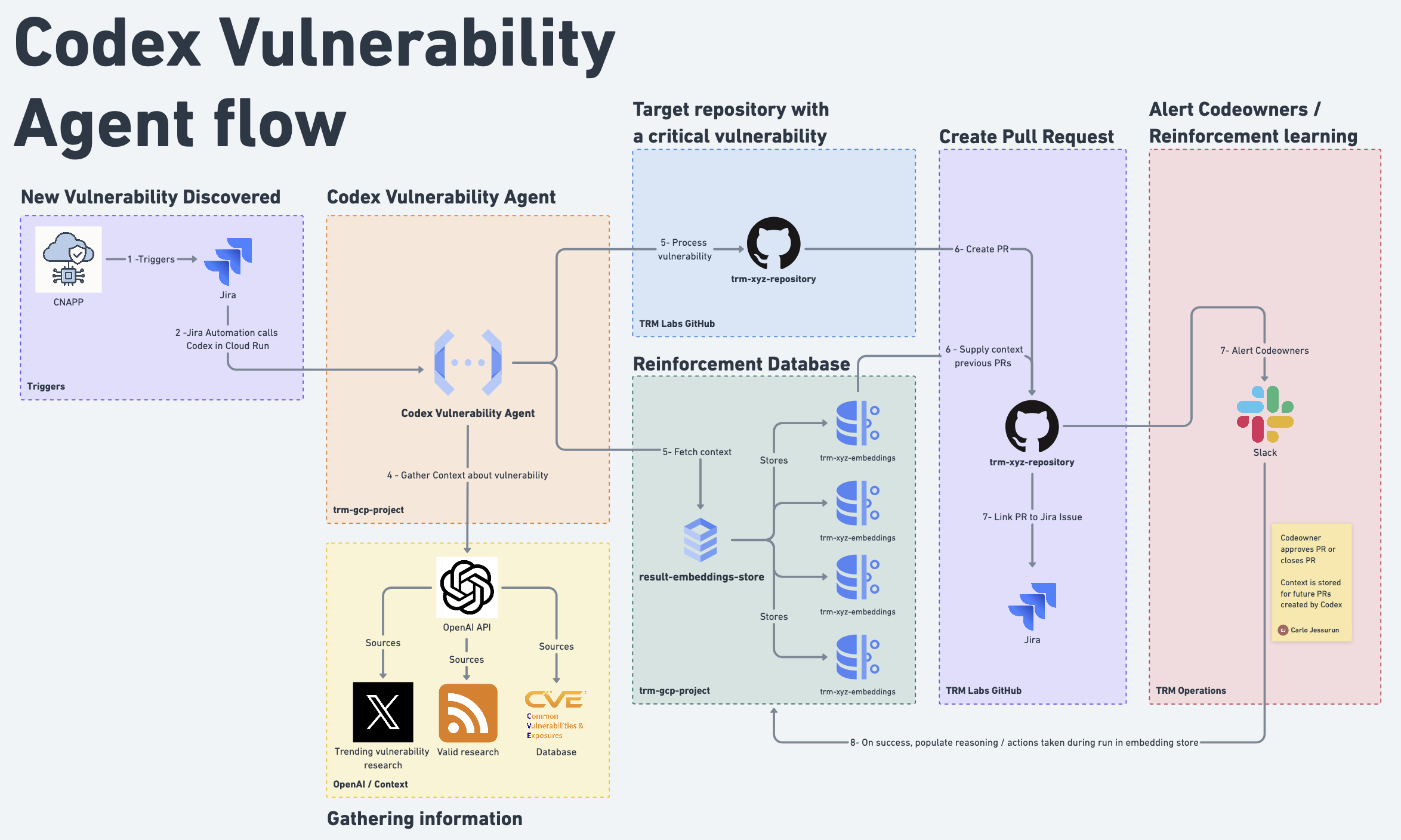
Stage 1: Vulnerability intake and processing
Our vulnerability intake pipeline begins with seamless integration across multiple security scanning platforms, including Wiz, Snyk, and GitHub Dependabot. When these tools identify vulnerabilities, they automatically trigger JIRA issue creation with structured vulnerability data. The Codex Vulnerability Agent then processes these JIRA payloads through sophisticated parsing logic that extracts critical metadata, regardless of which security tool generated the original finding.
To handle the scale of our vulnerability discovery — often 10-15 vulnerabilities per repository — we implemented intelligent batch processing that groups related vulnerabilities for efficient remediation. The system operates asynchronously to prevent JIRA Automation timeouts, immediately acknowledging vulnerability receipt while processing fixes in the background. This approach ensures our security workflows remain responsive even when processing complex repositories that may require 15–30 minutes of AI analysis and code generation. In addition, the system contextualizes each vulnerability by factoring in exploitability signals — such as the existence of publicly available exploits, the criticality of the affected service, and whether it is externally exposed — to minimize noise and ensure developer focus on the highest-impact issues.
Stage 2: AI-powered code generation
The core of our automation leverages OpenAI's Codex-RS, the native Rust implementation that delivers superior performance and memory efficiency compared to traditional JavaScript-based alternatives. We architected a two-phase approach that separates concerns for maximum reliability and consistency.
In the first phase, Codex-RS operates in full-auto mode within a carefully configured sandbox environment, applying vulnerability fixes directly to the local repository clone with comprehensive write permissions. This local-first approach eliminates the complexity and error-prone nature of having AI systems directly manage Git operations.
Once Codex-RS completes its analysis and code modifications, the second phase engages GitHub CLI to handle all repository management tasks including branch creation, commit formatting, and pull request generation. Our context-aware prompting system dynamically generates fix instructions based on the specific package manager (npm, pip, go.mod, Cargo.toml), vulnerability characteristics, and learned patterns from the target repository's history, ensuring each fix attempt is optimally tailored to the codebase's conventions and constraints.
Stage 3: Reinforcement learning and continuous improvement
Our reinforcement learning implementation continuously monitors the outcomes of every generated pull request to build an increasingly sophisticated understanding of what constitutes successful vulnerability remediation. The system tracks multiple success signals, including merge velocity, reviewer feedback, automated test results, and security tool verification of fixes to determine which approaches work best for specific repository patterns.
When pull requests are merged quickly with minimal revision requests, these successful patterns are stored in our context database as positive reinforcement examples. Conversely, rejected pull requests undergo failure analysis to identify common failure modes such as dependency conflicts, test breaks, or coding style mismatches. This historical context feeds back into future Codex prompts through adaptive learning algorithms that can recognize repository-specific preferences, coding conventions, and successful fix strategies.
Over time, this creates a virtuous cycle where the agent becomes increasingly effective at generating fixes that align with each development team's practices and requirements, resulting in measurably higher success rates and reduced manual intervention needs.
Implementation: From concept to production
Infrastructure stack
Our production infrastructure combines two primary Google Cloud services to deliver both immediate vulnerability processing and long-term learning capabilities.
Google Cloud Run serves as our compute platform, hosting the containerized Codex Vulnerability Agent that handles real-time vulnerability intake, AI-powered code generation, and pull request creation. Complementing this, Google Cloud SQL with the pgvector extension enabled provides persistent storage for our reinforcement learning system, storing historical pull request outcomes, successful fix patterns, and repository-specific context as vector embeddings. This CloudSQL vector database enables fast similarity searches when the AI agent needs to identify relevant historical patterns for a new vulnerability, allowing us to retrieve contextually similar successful fixes within milliseconds.
The combination of serverless compute for processing and managed vector storage for learning creates a robust foundation that can handle both the immediate demands of vulnerability remediation and the long-term data requirements of continuous improvement through reinforcement learning.
Google Cloud Run (Serverless container platform)
├── Docker containerization with Codex-RS, Git, GitHub CLI
├── Google Cloud Build (Automated CI/CD)
├── Google Secret Manager (API keys and tokens)
└── Terraform (Infrastructure as Code)Why Cloud Run
We selected Google Cloud Run as our deployment platform after evaluating several alternatives, including Google Kubernetes Engine (GKE), Compute Engine VMs, and AWS Lambda. Cloud Run's serverless container architecture proved ideal for our vulnerability processing workload, which is inherently bursty and unpredictable — we might process zero vulnerabilities for hours, then suddenly receive 15 vulnerability reports requiring immediate attention. The platform's ability to scale from zero to multiple concurrent instances within seconds perfectly matches our cost optimization goals, ensuring we only pay for compute resources during active vulnerability processing rather than maintaining idle infrastructure.
This scale-to-zero capability is particularly valuable given that our Codex Vulnerability Agent requires substantial computational resources (8 CPU cores, 16GB memory) to run AI model inference and repository operations efficiently. Unlike traditional serverless platforms that impose strict runtime limitations, Cloud Run supports our full containerized environment, including the native Codex-RS binary, Git tooling, and GitHub CLI, while providing up to 60 minutes of execution time per request — essential for processing complex repositories with extensive dependency trees.
The fully isolated container environment ensures that each vulnerability processing request operates in a clean, secure sandbox without interference from concurrent operations, while automatic scaling handles traffic spikes during security incident response without any operational intervention from our team.
.png)
1. Codex-RS integration
We chose Codex-RS (native Rust implementation) over the JavaScript Codex CLI for several key advantages:
- Performance: 3x faster execution for large repository operations
- Memory efficiency: Lower memory footprint in containerized environments
- Reliability: Better handling of concurrent operations and timeouts
- ZDR support: Zero Data Retention compliance with enterprise security requirements
Configuration example:
# Codex-RS Example Configuration File
# Model configuration
model = "o4-mini"
# Full automation mode
approval_mode = "full-auto"
# Disable reasoning to avoid organization verification
model_reasoning_effort = "none"
# Provider configuration
[providers.openai]
name = "OpenAI"
base_url = "xxx"
env_key = "xxx"
# Sandbox details
[sandbox]
mode = "workspace-write"
writable_roots = ["/tmp"]
network_access = true
# Disable interactive features and TUI - CRITICAL for Docker
[ui]
interactive = false
tui = false
headless = true
disable_spinner = true
disable_progress = true
quiet = true
# Environment configuration for headless operation
[environment]
headless = true
docker_mode = true
disable_tty = true
disable_ansi = true
no_color = true
# History configuration with required fields
[history]
enabled = false
persistence = "none"
# ZDR-specific configuration
[zdr]
enabled = true
disable_response_storage = true2. Two-stage processing architecture
Stage 1 - Local editing: Codex-RS operates in full-auto mode with comprehensive permissions to edit files locally. This prevents error-prone PR creation by the AI and ensures consistent changes.
Stage 2 - PR creation:
GitHub CLI (gh) handles repository management:
- Create feature branches with structured naming
- Commit changes with standardized messages
- Generate pull requests with vulnerability context
- Link to JIRA issues for audit trails
We learned that Codex often autonomously decided to go ahead and either create separate PRs per file which often lead to strange PR chains, especially when we batch process vulnerabilities. This separation of concerns provides better error handling and more consistent PR formatting.
3. JIRA integration and batch processing
Our system supports both individual and batch vulnerability processing:
// Example JIRA payload processing
const { repository, vulnerabilities } = parseJiraDescription(jiraDescription);
const processingResults = await processVulnerabilities(vulnerabilities, repoDir);Key features:
- Fault tolerance: If one vulnerability fails, others continue processing
- Serial processing: Each vulnerability processed individually with full cleanup
- Enhanced branch naming: Includes JIRA issue keys for traceability
- Async mode: Returns immediate response for JIRA Automation compatibility
4. Reinforcement learning implementation
Context storage and learning
Our reinforcement learning system tracks PR outcomes to improve future fixes:
// Pseudocode for reinforcement learning pipeline
const reinforcementDatabase = {
successfulPRs: await fetchMergedPRs(repository),
rejectedPRs: await fetchClosedPRs(repository),
patterns: await analyzeSuccessPatterns(repository)
};
const enhancedPrompt = createCodexPrompt(vulnerability, reinforcementDatabase);Success signals:
- PR merged within 24 hours
- Zero comments requesting changes
- Automated tests passing
- Security tool verification of fix
Failure signals:
- PR closed without merging
- Multiple revision requests
- Test failures
- Reviewer feedback indicating incorrect approach
Adaptive context generation
The system builds repository-specific context from successful patterns:
- Package manager patterns: Learn preferred update strategies per repository
- Testing approaches: Identify which test patterns work best
- Code style: Maintain consistency with existing repository conventions
- Dependency constraints: Understand version compatibility requirements
Measuring impact: The data we're collecting
While our Codex Vulnerability Agent has transformed our security workflow, we're now establishing comprehensive metrics to quantify its real business impact. Before AI automation, critical vulnerabilities took 5-7 days to remediate and required 30-60 minutes of developer time for each vulnerability identified. We're now tracking key success indicators, including mean time to remediation (targeting <24 hours), auto-remediation percentage (targeting 80%+ for common vulnerabilities), and developer time savings across our 150+ repositories.
Our measurement strategy combines real-time monitoring through JIRA and GitHub analytics with developer surveys and security posture assessments. The reinforcement learning system continuously tracks PR success rates, enabling us to measure how effectively the Agent adapts to different repository patterns and coding conventions over time. We're particularly focused on quantifying the reduction in context switching that previously pulled engineers away from feature development.
We're committed to transparency about our AI automation journey. In six months, we'll publish a follow-up blog post with concrete metrics demonstrating time savings, before/after workflow comparisons, and detailed analysis of reinforcement learning effectiveness. This data-driven approach ensures we're delivering measurable business value that scales with our mission to protect civilization from AI crime, while providing actionable insights for other engineering organizations building similar autonomous security systems.
Key insights
Building an AI-powered vulnerability management system at TRM Labs demonstrates the transformative potential of combining autonomous agents, reinforcement learning, and modern cloud infrastructure. By automating the most time-intensive aspects of security maintenance, we've not only improved our security posture but also freed our engineering team to focus on innovation and feature development.
The key insights from our journey:
- AI agents excel at repetitive, well-defined tasks like vulnerability remediation
- Reinforcement learning significantly improves AI performance over time
- Production-grade AI systems require robust infrastructure and operational practices
- The ROI of AI automation compounds as the system learns and improves
As AI capabilities continue advancing, we believe autonomous security agents will become essential infrastructure for any organization managing complex software systems at scale.
The Codex Vulnerability Agent is part of TRM Labs' broader AI-driven infrastructure initiative. Our engineers are building the blockchain intelligence platform of the future to protect civilization from AI crime and build a safer world for billions of people.
Join our team
Our security engineers are building AI-powered autonomous agents that protect civilization from evolving cyber threats, tackling some of the toughest challenges in automated vulnerability management and AI-driven security at scale. We're scaling security across 100+ repositories, processing petabytes of blockchain data, and building the future of autonomous security remediation to fight crime and build a safer world for billions of people. Ready to revolutionize how security operates at scale? Think you can build better AI agents that outsmart both human attackers and AI-powered threats? Explore opportunities and apply today: https://www.trmlabs.com/careers
Article contributors
- Carlo Jessurun | Staff Cloud Security Engineer, TRM Labs
- Jayson Franklin | Head of Security, TRM Labs
- David May | Application Security Engineer, TRM Labs







