7 min
Why We Stopped Partitioning by Time (And What We Did Instead)
We migrated 500 billion rows off Postgres, ditched time partitioning, and landed P95 query latency under 3.5 seconds. Here's what we learned.
TRM Labs’ block explorer lets fraud investigators search, sort, and filter blockchain transactions in real time. An investigator opens an address and sees a paginated list of transfers. They may choose to change how the table is sorted or filter by a specific field. Every interaction is a query, and fraud investigations are time-sensitive — so performance matters.
In the spring of 2025, we migrated over 500 billion rows of blockchain transaction data that powers our block explorer off sharded Postgres onto an Apache Iceberg-first stack. We still kept Postgres for the more recent transaction data.
This post covers why time partitioning didn’t work well for this use case, and how a bucket-based layout helped.
The dataset
TRM supports 60+ blockchains in production. As of early 2025, our historical transactions table contained over 500 billion rows; more than 42 terabytes of compressed Parquet data when written in Iceberg format. We were spending over USD 100,000 a month to store that on SSDs in Postgres. The economics alone made migration necessary.
But the harder challenge wasn't storage cost; it was skew.
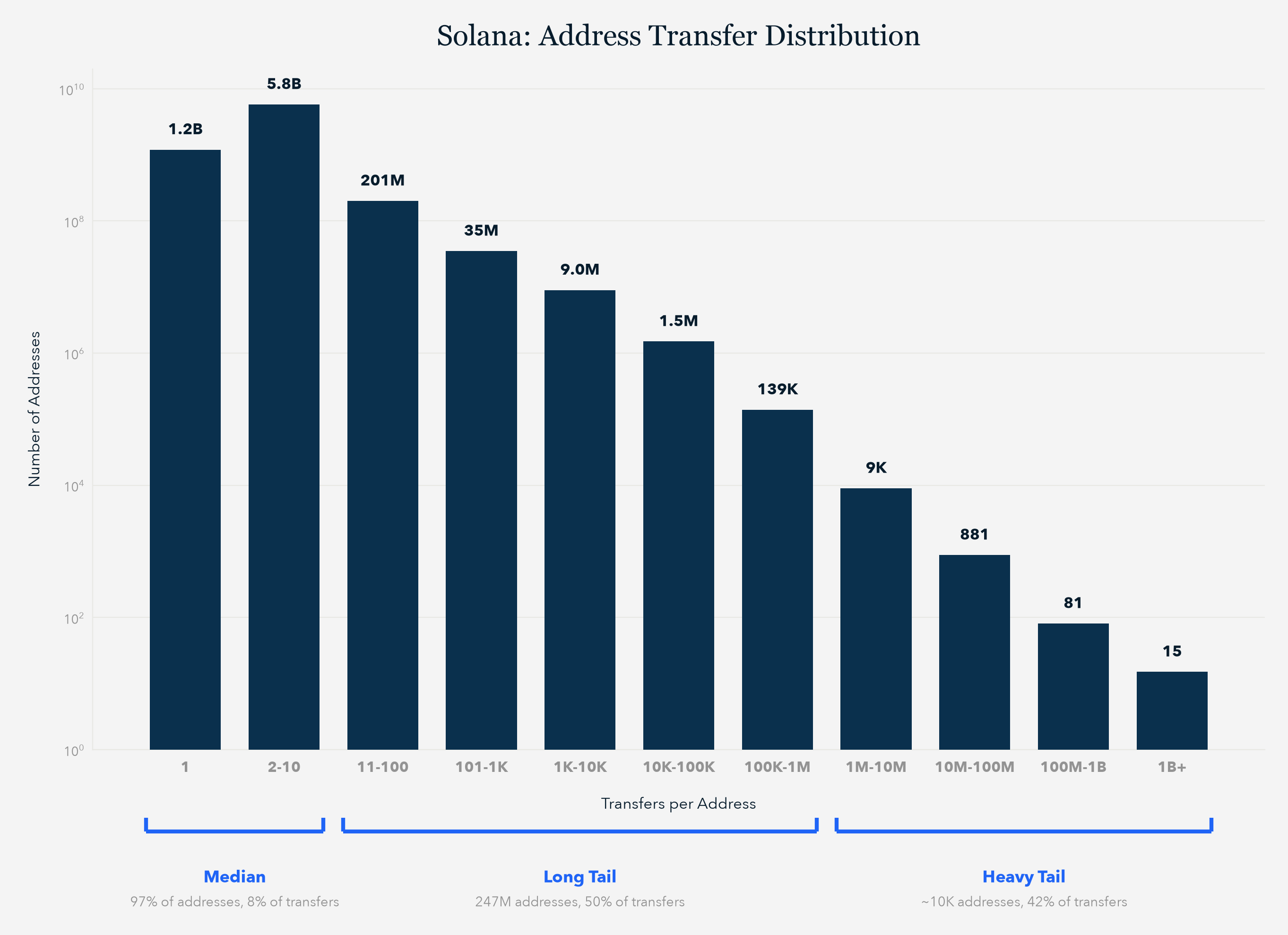
Above is a representative histogram from the Solana blockchain based on TRM data. The x-axis is the transaction count per address; the y-axis is the number of addresses at that level:
- Median: 97% of all addresses (close to 7 billion keys) account for 8% of total data volume — 1 to 10 transactions each
- Long Tail: 247 million addresses account for 50% of data volume — 11 to 1,000,000 transactions each
- Heavy Tail: ~10,000 addresses account for 42% of all data volume — 1,000,000+ transactions each
That's extreme skew. Nearly all the data lives in a small number of keys, and every layout decision we made had to serve both ends of this distribution simultaneously.
The access pattern
In 99% of queries, an investigator opens an address and gets a list of transfers sorted newest-first. The pseudo-SQL uses cursor-based pagination:
SELECT
t.timestamp,
t.direction,
t.counterparty,
t.amount_raw,
t.amount_usd,
t.asset,
t.tx_hash
FROM transfers t
WHERE t.address = :address /* Address is the key and part of every query */
AND (t.timestamp < :cursor_timestamp /* Majority of queries paginate by time */
OR (t.timestamp = :cursor_timestamp AND t.tx_hash < :cursor_tx_hash...))
ORDER BY t.timestamp DESC, t.tx_hash DESC, ...
LIMIT 100The remaining 1% of queries are sort-and-filter queries: sort by amount, filter to a specific counterparty, or find a specific transaction in a long history. Every sort or filter change fires a new query.
The latency target is under 3.5 seconds at P95 for all queries. Performance comes down to how much data you have to touch per query.
Why time partitioning failed
The obvious starting point for analytics data is time partitioning. A daily partitioned table was the first logical choice using Iceberg’s day hidden partition transform. Within each partition, we sorted by address and timestamp to match the 99% of queries’ cursor-based access pattern and the time-ordered nature of blockchains. Daily partitions keep writes cheap. You only need to append to today's partition during the nightly update cycle or rewrite the prior day’s partition to handle blockchain re-orgs or late-arriving data.
It broke at every point on our distribution:
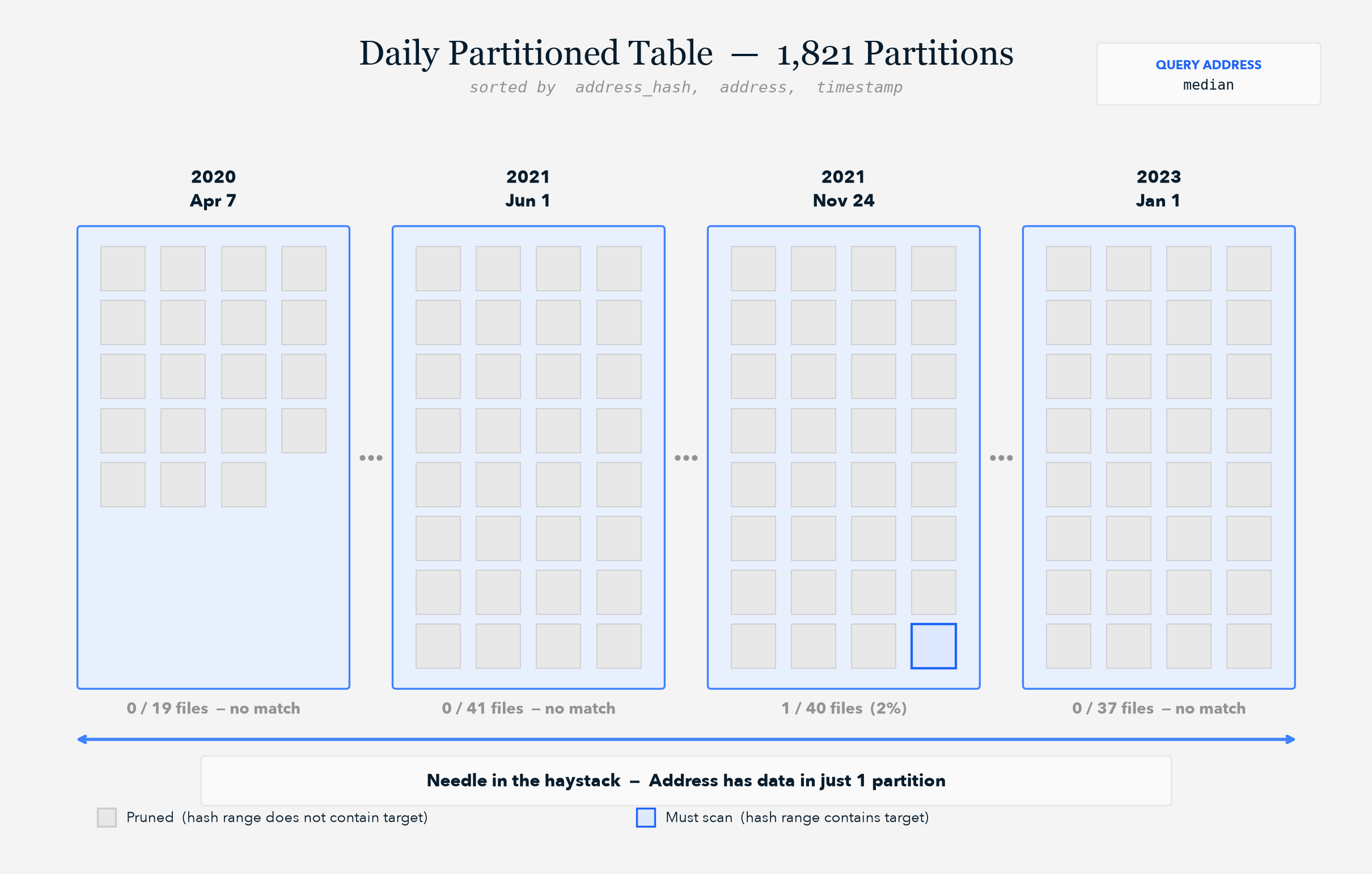
Median addresses (1 to 10 transactions) forced a needle-in-a-haystack scan across many partitions to find a handful of rows:
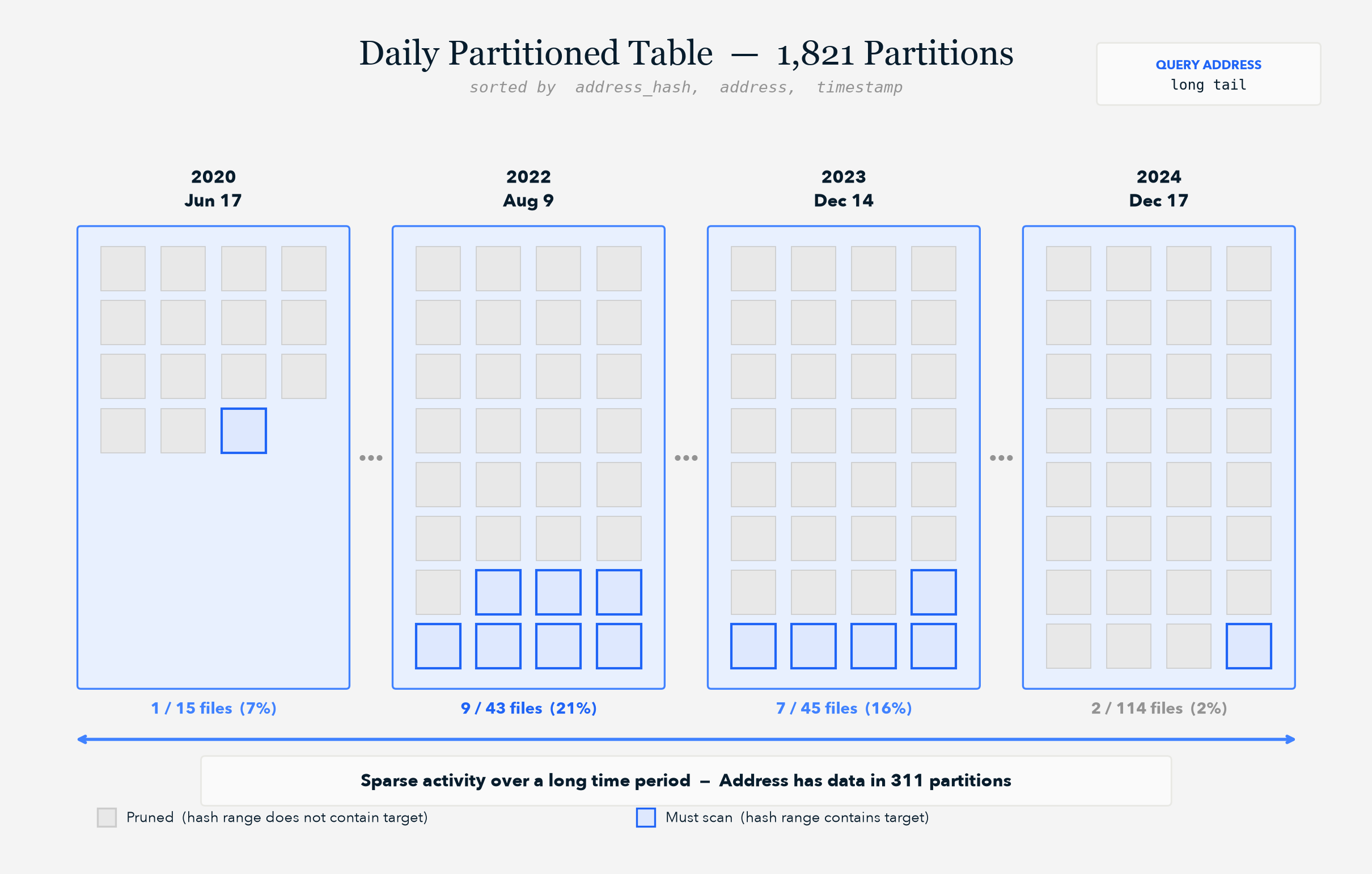
Long Tail addresses might have sparse activity spread across long time ranges, so you end up opening many partitions in the worst case:
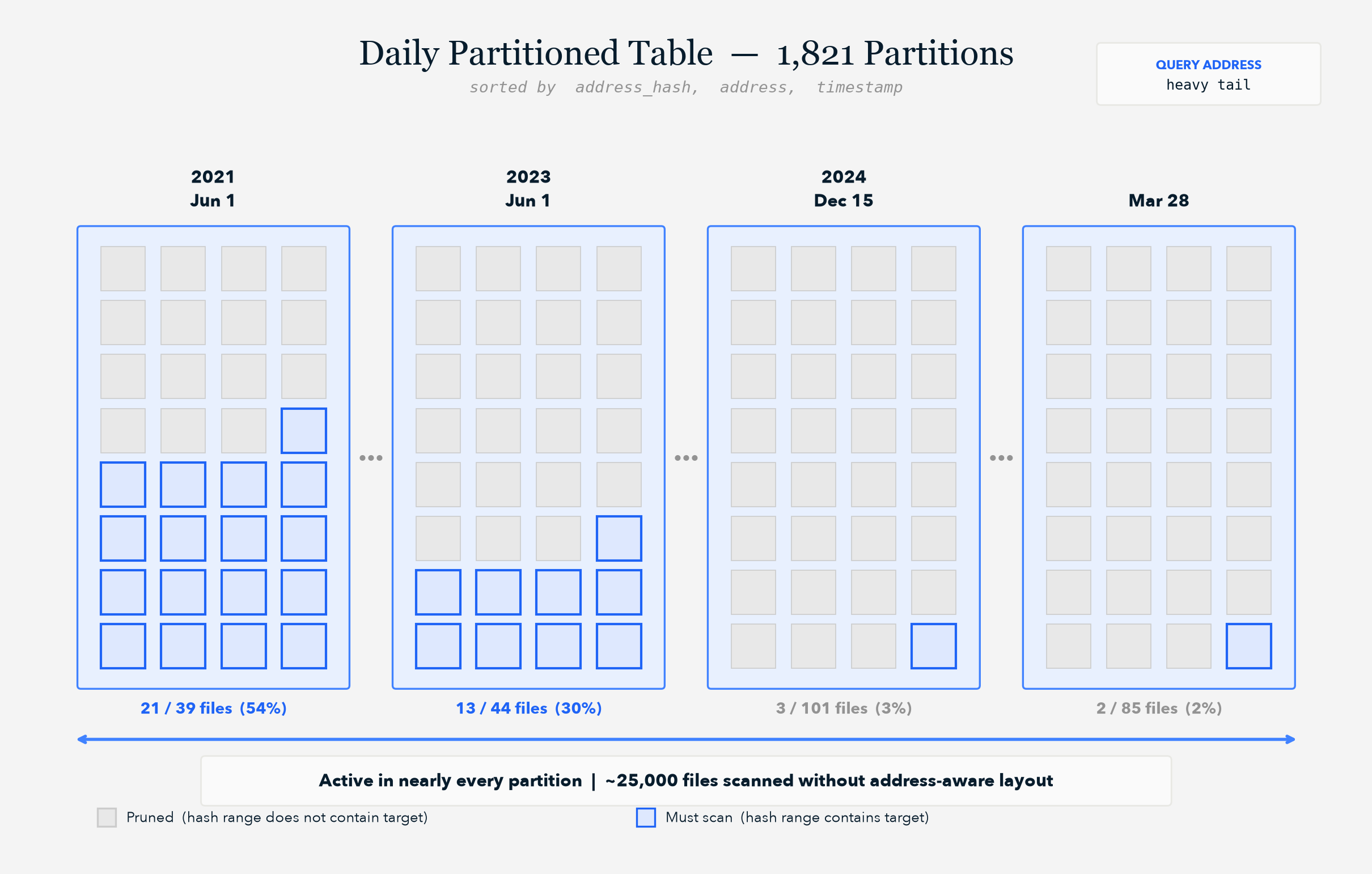
Heavy Tail addresses (those ~10,000 keys generating 42% of the data) exist in nearly all partitions. The reader has to open essentially all of them when sorting or filtering. There's no pruning to do.
What surprised us was obvious in hindsight:
- First, Iceberg metadata captures min/max statistics at the partition and file level, but time-based partition pruning only kicks in when the query has both an upper and a lower bound on the partition column. We tried auxiliary lookup tables that mapped each address to the partitions it appeared in, which narrowed the partition set for the 99% common-case queries. That didn't scale to the sort-and-filter queries because of the complexity of maintaining fact tables and histograms for every supported sort column.
- Second, the Iceberg specification doesn't require writers to honor the table sort order, so a reader can't trust files are sorted globally and has to fall back to file-level min/max bounds: “Writers should use this [a table’s] default sort order to sort the data on write, but are not required to . . .” (Iceberg specification).
- Third, because hot keys span every time partition, there's minimal pruning available when you need to apply a filter or sort, especially for Heavy Tail addresses. We tried coarser-grained partitions (monthly, yearly), but the skew lived inside the partitions regardless of granularity.
The key insight: file fan-out dominates read performance. This is an extension of the small files problem — too many files to open per query, and you become I/O bound. Partition granularity wasn't the lever. File count was.
The shift: Bucket by address, sort by time
We changed the layout to match the query rather than the data's natural time structure. We used Iceberg's bucket hidden partition transform on the address column, with data sorted by address and timestamp within each bucket.
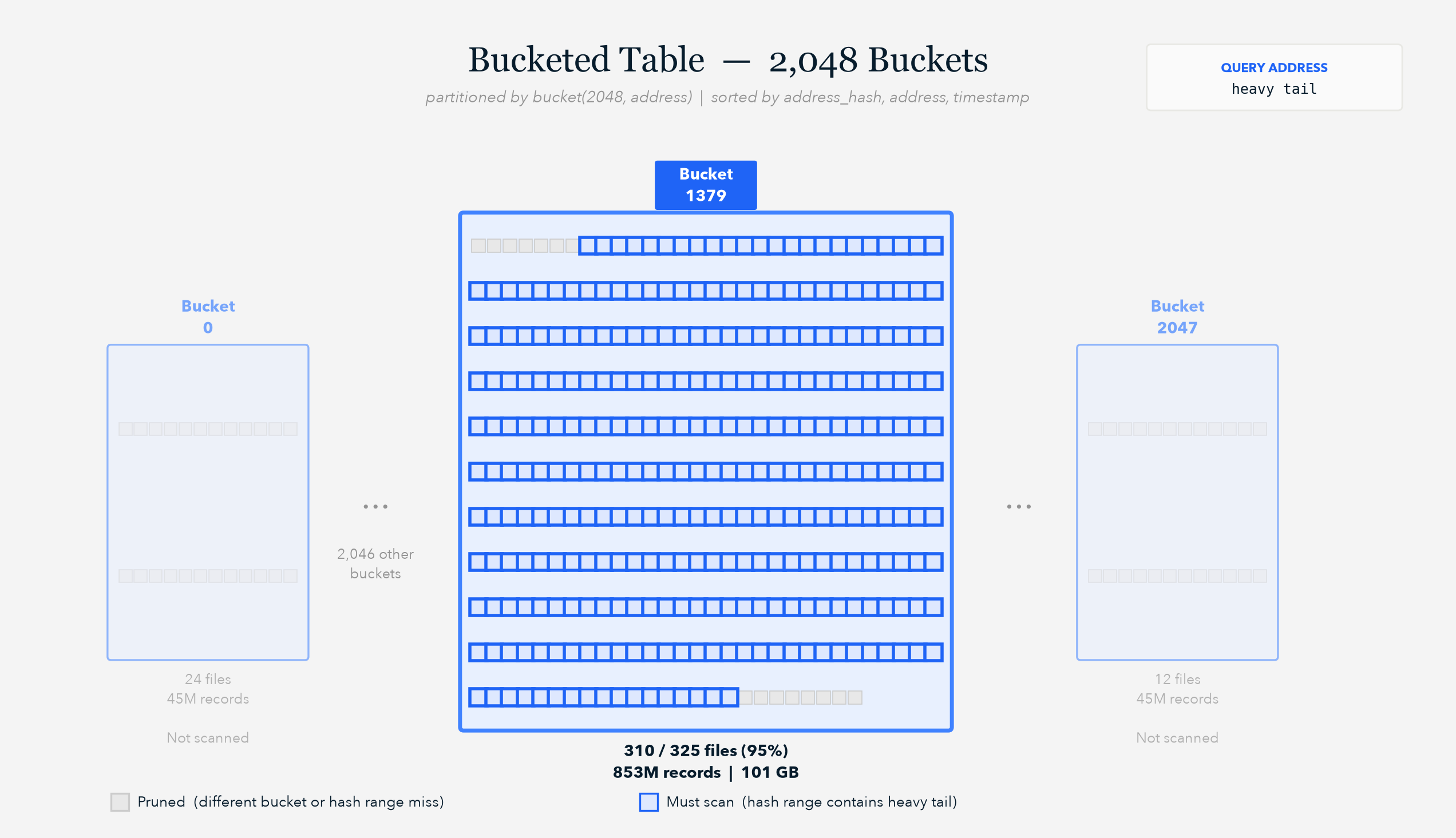
The benefits are concrete:
- Colocation: All transactions for a given address land in one bucket, which gives readers a single partition to open
- Compression: Sorting by address within a bucket improves table compression because data for a given address is clustered together
- Bounded file fan-out: In the worst case (Heavy Tail addresses), we go from scanning ~25,000 files under the daily layout to ~300 files with bucketing. Faster and predictable.
- Time-based pruning without time partitions: Because we sort by timestamp within each bucket, readers get time-range pruning at the file level for free. The paginated query pattern works without needing a separate partition axis for time.
Maintaining the layout
While bucketing reduced file fan-out on the read side, it introduced two challenges on the write side:
1. Write skew
The same data skew that broke reads also breaks writes. Spark jobs processing Heavy Tail keys generated straggler tasks and shuffle fetch failures. Our fix: isolate the top skewed keys and process them in a separate write path from all the non-skewed keys. We implemented dual-level partitioning in our final DDL, using an is_skew identity partition to separate extreme keys as the first partition column, then bucketing as the second level on address. By processing skewed data separately from non-skewed data, Spark’s Adaptive Query Execution split shuffle partitions more evenly at the final repartition and write stages, so our jobs no longer failed during shuffle.
2. Incremental updates create layout drift
Blockchain data isn't append-only. Corrections are common due to re-orgs or decoding errors. Addresses are distributed uniformly across the key space, so updates and corrections hash into nearly all buckets. Small files accumulate on every update cycle, bucket sizes drift, and file counts climb. This degrades read performance gradually. Compacting every partition on every update cycle is expensive, and there isn't always time to do it before the next update lands.
3. Full rewrites are the answer
Rather than trying to compact incrementally, we rewrite entire tables on a regular cycle. A full rewrite resets the layout, keeps file sizes predictable, and requires only snapshot expiration and orphan file removal. The cost is lower than it sounds: rewriting the Bitcoin table runs for under USD 7 per run. That's negligible compared to what we were spending on SSDs.
Tuning bucket counts
Bucket count is a workload parameter, not a schema decision. Too few buckets and you get hot buckets still carrying too much data. Too many and you accumulate small files and metadata overhead.
We've had good results keeping bucket sizes between 5 and 25 GB based on logical data size, using power-of-two bucket counts. For the most skewed keys that we put into the is_skew partition, their bucket size can exceed 25 GB. They are not on the hot read path, but we plan to revisit them. We set the initial counts when we launched and haven't had to touch them in over a year of production use, though we're approaching the point where we'll need to revisit some tables as data continues to grow.
Results
After more than a year in production on a large StarRocks cluster, the bucketed layout holds the latency target comfortably. Over the last seven days, across 280,000+ paginated queries, P50 is ~1.0s and P95 is ~2.5s (service level objective: ≤ 3.5s). By cutting the number of files the query engine has to open per query, the bucketed layout gives us that headroom.

Takeaways
- Measure files scanned, not just bytes scanned: Too many files and your queries will be I/O bound.
- Bucket for your access pattern, not your ingestion pattern: Time partitioning is a natural fit for time-series analytics. It's not the right model for cursor-paginated, address-keyed lookups.
- Full rewrites can be cost-effective and simpler than incremental compaction: At our scale, the simplicity of a clean periodic rewrite beats the complexity of tracking and doing nightly compaction.
- Bucket counts require ongoing attention: Treat them like capacity planning, not a one-time schema choice.
We're continuing to push P95 further on Heavy Tail addresses and working on more automated table management for operating Iceberg at this scale. If these problems are interesting to you, we're hiring on the data platform team.
{{horizontal-line}}
This blog post is based on a talk given at the 2026 Iceberg Summit by TRM Labs: Taming the Heavy Tail: Buckets + Rewrites for Fast Iceberg Serving.
{{tech-blog-test}}







