10 min
Building an Agentic Software Factory: How TRM Re-architected Engineering for AI Leverage
How TRM treated AI as platform infrastructure — not personal tooling — to hit 125% of OKRs, onboard chains at 3x the previous quarterly record, and keep human judgment at the center of engineering decisions.
The default move when AI lands in your engineering org is to give every engineer more tooling. We didn't. We treated AI as platform infrastructure — with explicit human-only decision points for the calls that actually matter: promotion, hiring, architecture, and accountability.
Across the core ingestion teams in Q1 2026, that operating model helped us hit 125% of our OKRs, onboard chains at 3x the previous quarterly record, cut targeted infrastructure spend, and ship launches with fewer follow-ups. The lesson wasn't "use AI everywhere," but build an agentic software factory where repeatable work is automated, review moves upstream, and humans keep ownership of judgment.
These examples come from TRM's blockchain data organization, but the operating model generalizes to any engineering team where AI is increasing output faster than existing review, planning, and operating systems can absorb it.
Key takeaways
- Platform, not personal tooling: Local experiments only compound when they become shared, permissioned, observable workflows.
- Explicit responsibility boundaries: Some work is AI-first, some AI-assisted, some human-led with AI evidence, and some human-only. Decide in advance.
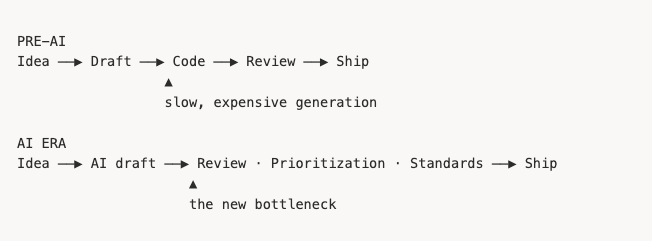
- Redesign for review, not generation: AI makes code cheap to produce. The bottleneck moves to quality, prioritization, and verification.
- Turn local wins into defaults: A one-off prompt helps one engineer. A platform workflow compounds across teams.
- Reward leverage, not volume: Durable systems work matters more than PR count.
What changed
* The OKR result is not a claim that goals should stay fixed while AI makes teams faster. We treat it as a planning-system signal: the next planning cycle raises the bar by calibrating goals against AI-assisted throughput from the start.
** Infrastructure savings refer to annualized run-rate reduction on specific targeted ingestion infrastructure lines. This is not total company infrastructure spend and not token spend alone.
*** Launch-quality metrics are scoped to confirmed P0 incidents tied to chain-launch scaffolding in the measured rollout period, not a claim that all on-call noise disappeared.
The organizing contract: Four responsibility buckets
The factory only works if every AI capability declares what kind of work it's allowed to do.

AI-first work is generated by AI; humans review opportunistically. Summaries, PR scaffolding, release drafts, and triage digests.
AI-assisted work is drafted by AI, but the human owns the final artifact. First-pass review, incident synthesis, and interview prep.
Human-led + AI evidence work is driven by humans, with AI organizing the supporting material. Performance drafting, debrief synthesis, and planning support.
Human-only work is where AI may inform context, but the final decision stays with people. Promotions, final hiring decisions, architecture tradeoffs, and accountability calls.
These boundaries are what keep the factory safe to scale. Without them, you either end up with a collection of disconnected productivity hacks or a black box making decisions it shouldn't.
What forced the change
In Q4 2025, AI-assisted coding adoption inside the org crossed a threshold where output started outpacing the systems we had for absorbing it. PR review queues lengthened. Chain coverage increased on-call surface area. Every engineer was experimenting with AI in their own way, but without shared evals, shared workflows, or shared guardrails. Performance reviews got harder to calibrate — raw activity was easier to inflate while real systems work was still hard to fake.
We tried the obvious things first: more individual AI tooling, more manager involvement, more review meetings, more autonomy. Each helped locally; none of them scaled. What actually worked was the moment we stopped treating AI as a collection of personal tools and started treating it as shared engineering infrastructure with explicit human decision boundaries.
Pillar 1: Repeatable work runs on a platform, not on prompts
The first shift was moving from individual AI usage to shared AI infrastructure. A prompt helps one engineer. A local script helps one workflow. But a platform capability helps the team, repeatedly.
At TRM, the platform layer is AskNickiBot, our internal agent platform. It discovers skills across repos, runs retrieval and feedback loops, and centralizes OAuth, per-tool permissions, and audit logs. A skill author writes the skill; the platform handles the shared infrastructure around it.
The valuable work wasn't "use AI more." It was turning recurring engineering tasks into reliable defaults: chain-launch scaffolding, AI-first PR review, on-call triage summaries, launch templates, structured incident writeups, performance-review evidence packs, hiring-debrief summaries. The platform handles discoverability, permissions, auditability, retrieval, evals, and feedback loops once. Teams don't reinvent safety, access control, or review patterns for every new AI workflow.

Pay the standardization cost once, recover it many times.
Pillar 2: Quality control moves upstream
AI changed where review work had to happen — it didn't remove it.
Once generation got cheaper, the scarce resource became human attention: review quality, prioritization, standards, and launch judgment. If managers don't redesign the review loop, the bottleneck just moves downstream in the SDLC.
This is where AI slop becomes a real operating problem. The issue isn't just that AI can generate more artifacts — it's that AI can generate plausible-looking artifacts that require more review per artifact.
So we redesigned the loop around a simple principle:
Human reviewers should see second drafts, not raw AI output.
In practice: smaller batches, AI feedback shifted to authors before human review, comprehension checks before reviewer time is spent, explicit author sign-off, structured launch and review templates, and clearer ownership for final decisions.
The engineer still owns the diff. AI compresses the path to a reviewable first draft. Human reviewers spend less time finding the obvious problems and more time on correctness, architecture, edge cases, and tradeoffs. The point isn't to replace review — it's to protect reviewer attention for the decisions only humans can make.
Pillar 3: Judgment stays human
Architecture tradeoffs and accountability calls stay with people. The platform produces evidence; humans decide.
AI can summarize an incident, synthesize feedback, prepare interview notes, or organize evidence for a performance review. It shouldn't decide whether someone is promoted, whether a candidate is hired, whether an architectural risk is acceptable, or whether an accountability call needs to be made. Those are human-only calls, full stop.
Worked example: Launching a new chain
A chain launch shows the operating model in miniature.
New chain launches at TRM used to take weeks of PR scaffolding before an engineer could focus on the chain-specific logic. Now the repeatable parts are compressed into a platform workflow.
1. AI-first: Generate the repeatable path
The launch starts as AI-first work.
AskNickiBot, fed a chain spec, produces the launch workflow across relevant systems — identifying tasks, assigning likely owners, estimating delivery dates based on historical patterns, and generating the initial PR scaffold across the relevant repos. That scaffold can include adapter stubs, schema migrations, dataset registration, on-call wiring, streaming producer templates, and a launch checklist.
The engineer doesn't spend days typing repeatable code. Instead, the platform produces the path.
2. AI-assisted: Move review upstream
The engineer fills in the chain-specific logic: block format quirks, signature schemes, reorg semantics, edge cases, data-quality checks.
Before any human reviewer sees the PR, the engineer runs the AI-first reviewer. It reads the diff, flags likely issues, generates a comprehension checklist, and requires the author to confirm understanding before human review.
The engineer owns the diff and AI compresses the path to a reviewable draft. That means human review starts from a cleaner artifact.
3. Human-only: Make the launch call
Whether the chain meets support-tier criteria, whether the first 24 hours of data quality are good enough to flip customer-facing flags, whether SLOs are within accepted limits, whether to delay launch or push through a known edge case: those calls sit with the chain owner or on-call lead — and on the harder ones, the manager.
The platform produces evidence and structured staging reports. Humans decide and sign the launch.
That's the factory in one example: automate the repeatable path, move quality gates earlier, keep launch judgment with accountable humans.
What this changes for people
The factory changes how engineering throughput works. It also changes what great engineering looks like.
Raw PR output is easier to inflate in the AI era. But reusable systems work is still hard to fake. The engineers creating the most value aren't always the ones with the most PRs — they're the ones building reusable systems, creating better defaults, improving review loops, growing other engineers, and turning local wins into team capability.
That changes promotion calibration. The promotion doc is a lagging indicator of work shaped over quarters, so the manager's job is to create conditions for that evidence to exist — the right project, the right written artifacts, the right cross-functional exposure. Each step up the engineering ladder should represent a different kind of work: shipping features, removing toil, building reusable systems, setting team standards, growing other engineers, running cross-team programs, improving the operating model itself. AI can summarize the evidence pack and cluster cross-functional feedback. The level call lives with the manager and calibration committee.
Hiring also has to adapt. The goal isn't to ban AI or pretend candidates won't use it — it's to design a loop that evaluates judgment, comprehension, debugging ability, code quality, and ownership in an AI-assisted environment. That means replayable exercises, structured scorecards, code-quality visibility, candidate-understanding checks, proctoring where appropriate, and automated debrief summaries with explicit interviewer calibration. AI helps with prep, note synthesis, and debrief summaries. Final hiring decisions stay human.
And the human parts of leadership get more important, not less. When the team moves faster, people need clearer recognition, better context, and more explicit growth conversations. Two habits did most of the work: kudos that named the specific behavior demonstrated rather than generic praise, and career pathway docs maintained during the period rather than reverse-engineered at packet time.
The whole system sits on top of TRM's Leadership Principles more than any single management framework. Accountability staying human, coaching happening early, treating shared AI capability as craft worth investing in — those are why the system has the shape it does.
One operating system, multiple team contexts
The same operating model worked across pods with very different shapes.
Software engineering (ingestion) is streaming-dense. Cross-chain swap is data science-heavy and graph pattern-dense. Both pods now share planning patterns, on-call rotation, launch templates, platform capabilities, and review loops. The system absorbed two pods without doubling management overhead.
That was the test that mattered. We weren't trying to make every team identical — we were standardizing the parts that should compound (platform workflows, review gates, launch paths, responsibility boundaries) while preserving local judgment where the work actually differs.
What's next
Three things are on deck for the next cycle.
Function-level demo day / MBR: Team-level workflows are working, but the function-level rhythm is still emerging. We're standing up a quarterly cadence so cross-pod context flows without ad-hoc Slack threads.
Building the agentic platform: We're consolidating the AI agentic platform to serve most of TRM through common infrastructure, with add-ons for team-specific use cases.
More capabilities in the human-led + AI evidence bucket: Performance review drafting is the most mature today. Hiring debriefs and architecture decision drafting are next. Each new capability ships with the same security stack, eval discipline, and human-decides contract.
If you're building an agentic software factory, start here
- Define the human-only decisions first: Promotions, final hiring, architecture tradeoffs, accountability calls. Make the line explicit before AI is anywhere near the work.
- Standardize one high-volume workflow: Pick whatever the most people repeat — releases, on-call triage, performance drafting, PR review — and turn it into a reliable default before scaling more.
- Move AI feedback upstream to authors: Comprehension checks, AI-first review, batch-size limits. Reviewers should see second drafts, not first drafts.
- Reward leverage, not volume: Reusable systems, playbooks, multi-team programs, better defaults, engineers grown — these matter more than raw activity.
- Pick one shared platform path and stop fragmentation: Multi-repo discovery, OAuth, audit logs, evals, and feedback loops should be solved once, not reinvented per workflow.
AI-assisted coding changes the economics of engineering. More tools for every engineer isn't the answer. An agentic software factory with clear responsibility boundaries is: automate repeatable work, move review upstream, keep judgment human.
Interested in this kind of work? We're hiring engineers and managers who like distributed systems, AI platform infrastructure, and high-quality engineering culture.







