18 min
Scaling Security in the Age of AI, Part 2: How One Agent Triages, Remediates, and Approves Across TRM
TRM rebuilt its single-purpose CVE patch agent into a unified Slack-native orchestrator that autonomously triages every security alert, reviews every infrastructure PR, answers every helpdesk question, and — for a narrow set of well-understood patterns — closes the loop without asking a human.
Late last year, we wrote about TRM Labs' first vulnerability agent, our first attempt at putting an AI in front of our security posture. It paired an LLM with a reinforcement-learning loop over months of merge / revert / comment signals, and was generating production-ready PRs across 150+ repositories and clearing hundreds of critical vulnerabilities a month with zero engineer time per fix.
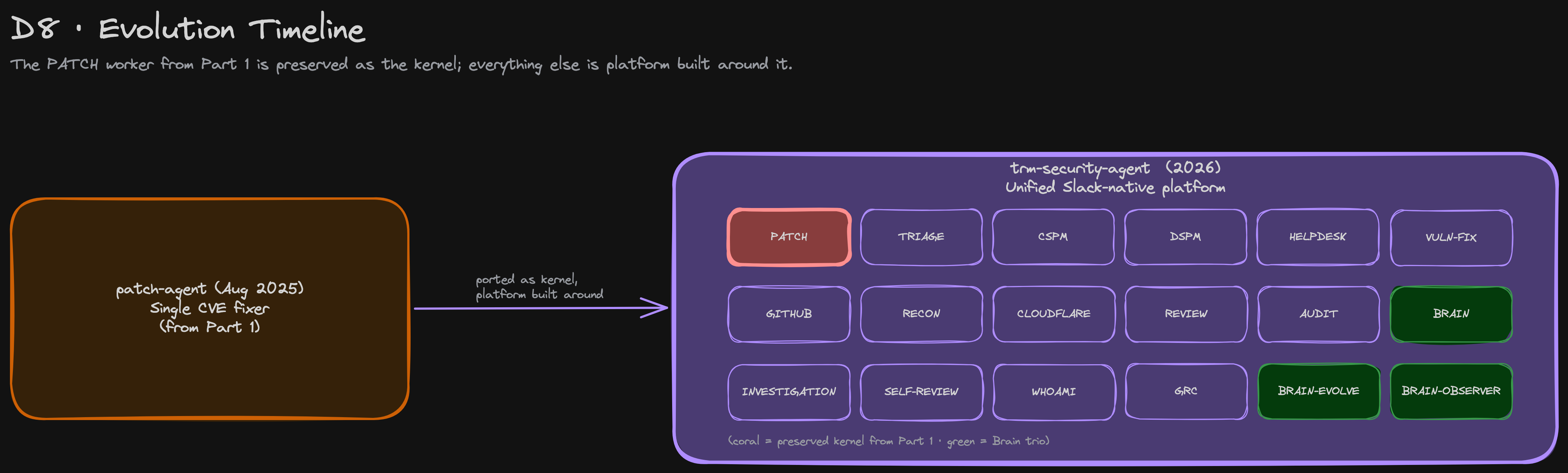
Six months later, the single-purpose patch agent has outgrown its name. The same kernel that opened those CVE PRs now runs a unified Slack-native orchestrator that autonomously triages every alert in our security alerts Slack channel, reviews every infrastructure PR, answers every question in our IT help channel, and — for a narrow set of well-understood patterns — closes the loop in the source system without asking a human.
What follows is the architecture of that pivot, the workflows it now runs, what we learned operating it as a production service, and the outcomes it unlocked for our team: the on-call toil it reclaimed and the security coverage it scaled without adding headcount.
Key takeaways
- Every security workflow has the same five-step shape: Alert → investigate → diagnose → fix → close. Only the tools change; the unlock that turned one agent into a platform.
- Slack is the UI, not the integration target: The agent posts, asks, and acts in-thread. Anything that pulls engineers to a new console gets ignored.
- Tool subsetting beats prompt engineering: Giving the model the eight tools relevant to the current channel produces sharper decisions than offering all 56.
- Autonomy on a leash: Agent approval of PRs is scoped to well-understood, low-risk patterns; everything else escalates with enriched context attached.
- SRE for AI agents: Per-workflow SLAs and one shared telemetry pipeline are what made multi-workflow scale possible, not model upgrades.
{{horizontal-line}}
What changed
“Decisions per 30 days” counts orchestrator interactions across all four workflows. “Auto-resolution” varies by workflow: helpdesk reaches 45% in the strict sense (no ticket created) and is meaningfully higher with assist; security-alerts auto-closes 17% of incoming alerts and escalates the rest with enriched context; review approves a narrow, curated set of low-risk infra patterns and routes everything else to a human reviewer. See the SLA framing later in the post.
The problem
The shape of security work without an orchestrator
Once dependency upgrades were automated by the original patch agent, every other security workflow at TRM still looked exactly like the old one.
An on-call engineer gets a CSPM alert at 2:00am, pastes the asset ID into a runbook, queries GCP for the owner, checks the CSPM tool for prior closures, writes a paragraph in Slack, and closes the ticket by hand. A different engineer gets a DSPM alert and runs the same pattern through a different toolchain. A third reviews a terraform fmt-only PR. Same five-step shape (alert → investigate → diagnose → fix → close), different tools every time.
That asymmetry was the bottleneck. Automating one workflow doesn't take pressure off the team; it raises the embarrassment level when the next alert still gets handled by hand. We needed a platform whose shape matched the shape of the work, and whose intelligence layer could grow with the team rather than being scoped to a single integration.
From a code-patching Slackbot to an autonomous security platform
Why a function-shaped patch agent couldn't generalize, and what shape replaced it
The original patch-agent codebase was structurally a function: in a CVE, out a PR. Beautiful for one workflow, but useless for the next one.
When we sat down to design what came after, one observation shaped everything else:
Every security workflow has the same five-step shape — alert → investigate → diagnose → fix → close. Only the tools change.
Two more observations followed:
- Engineers already lived in Slack: Anything that asked them to context-switch to a new UI would be ignored.
- Autonomy compounds when one agent learns across workflows: A runbook discovered while closing one alert should make the next alert faster, not be locked inside a single integration.
The answer was an orchestrator-workers architecture with Claude Opus as the dispatcher. Skills are added one at a time and registered in a central catalog that drives prompt assembly and tool subsetting. We preserved the patch-agent's Cloud Run + Claude Code worker loop verbatim, dropped it in as the kernel for the patch skill, and built outward.
The bot today runs 14 user-invocable skills plus one operational triage section, exposing 56 tools in total.
Design principles
Five non-obvious operating disciplines that shape every skill on the platform — the unglamorous controls that make multi-workflow scale safe, observable, and affordable
1. Human gates on irreversible actions
For anything with meaningful blast radius, the agent runs a risk analysis, posts a Block Kit report with Proceed / Cancel buttons, and waits. Claude is never in the confirmation loop for destructive operations — Slack interactivity is. The agent creates PRs; humans merge them. The agent drafts brain-evolve runbooks; humans review and merge them.
2. Cost transparency per workflow
From the start, we wanted to understand exactly what the agent costs — not in aggregate, but per interaction, per workflow. Today we track cost at the transaction level: helpdesk runs at USD 0.16/interaction, PR review at USD 0.25/interaction, alert triage at USD 0.29/interaction. This granularity drives architectural decisions.
The regex → Haiku → cache → Opus pipeline in the review workflow, for example, was designed specifically to avoid hitting Opus for intent classification; Haiku handles that in ~200ms for a fraction of the cost. Knowing what each workflow costs per interaction lets us reason about trade-offs clearly: Is the auto-resolution rate worth the spend? Where does caching pay off? What's the right model tier for each step?
3. High availability through environment isolation
A single bad push can't take down production. We run two Cloud Run services from the same image — prod and staging — sharing one Slack app, one Firestore database, and a single Pub/Sub fanout. A single agents-config.yaml file declares which Slack channels each service owns; every engineer can spin up their own staging channel for experimental PRs, and the fanout silently drops events for channels a service doesn't own. Per-branch revisions in the staging service let two engineers iterate in parallel without contention.
4. Test every incident, prevent the next one
We have 1,100+ QA tests that must pass before every merge, organized across three axes: Performance (cache behavior, TTLs, cardinality), Availability (timeout discipline, webhook correctness, deployment-shape invariants), and Security (auth model, prompt-injection fences, SSRF allowlists, hard-blocks on destructive git ops). Every test reads like an incident postmortem — annotated with the bug, date, and channel it broke in. Every production incident produces a new test file. The same class of incident hasn't recurred.
5. The system gets smarter as the team works
Every live triage, PR review, and helpdesk reply feeds a capture_brain_observation flywheel that surfaces documentation gaps and drafts improved runbooks via brain_evolve. The agent's knowledge base compounds over time through the ordinary work of the team flowing back into the corpus it reasons over.
Inside the platform
One Cloud Run service, one orchestrator loop, three execution patterns, and one shared catalog of tools
Architecturally, the agent looks deceptively simple: every Slack event lands in a single Cloud Run service, where Claude Opus runs a while (tool_use) loop with adaptive thinking. The loop picks tools, executes them, and posts back into the originating Slack thread. The interesting parts are below that surface.
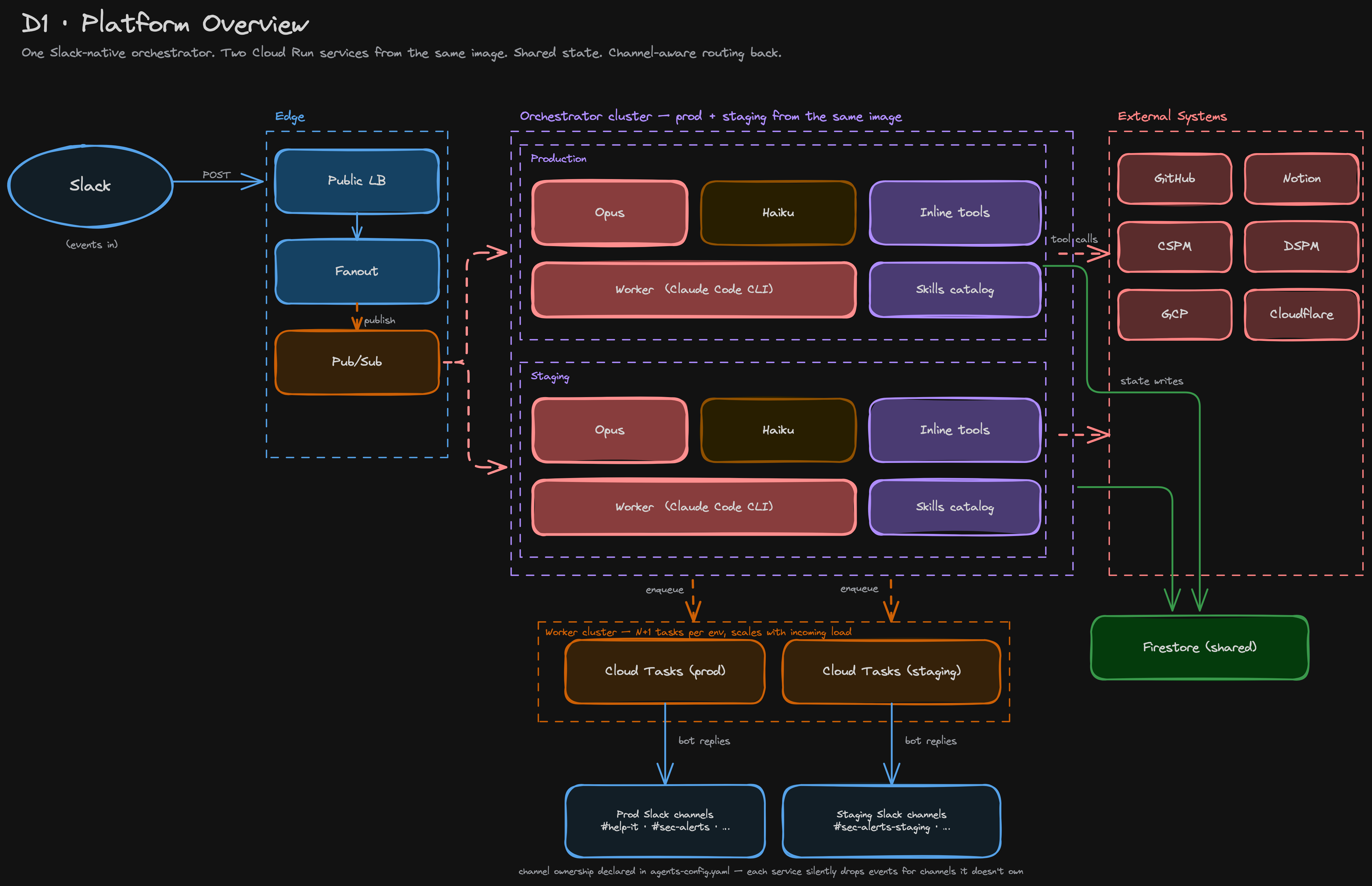
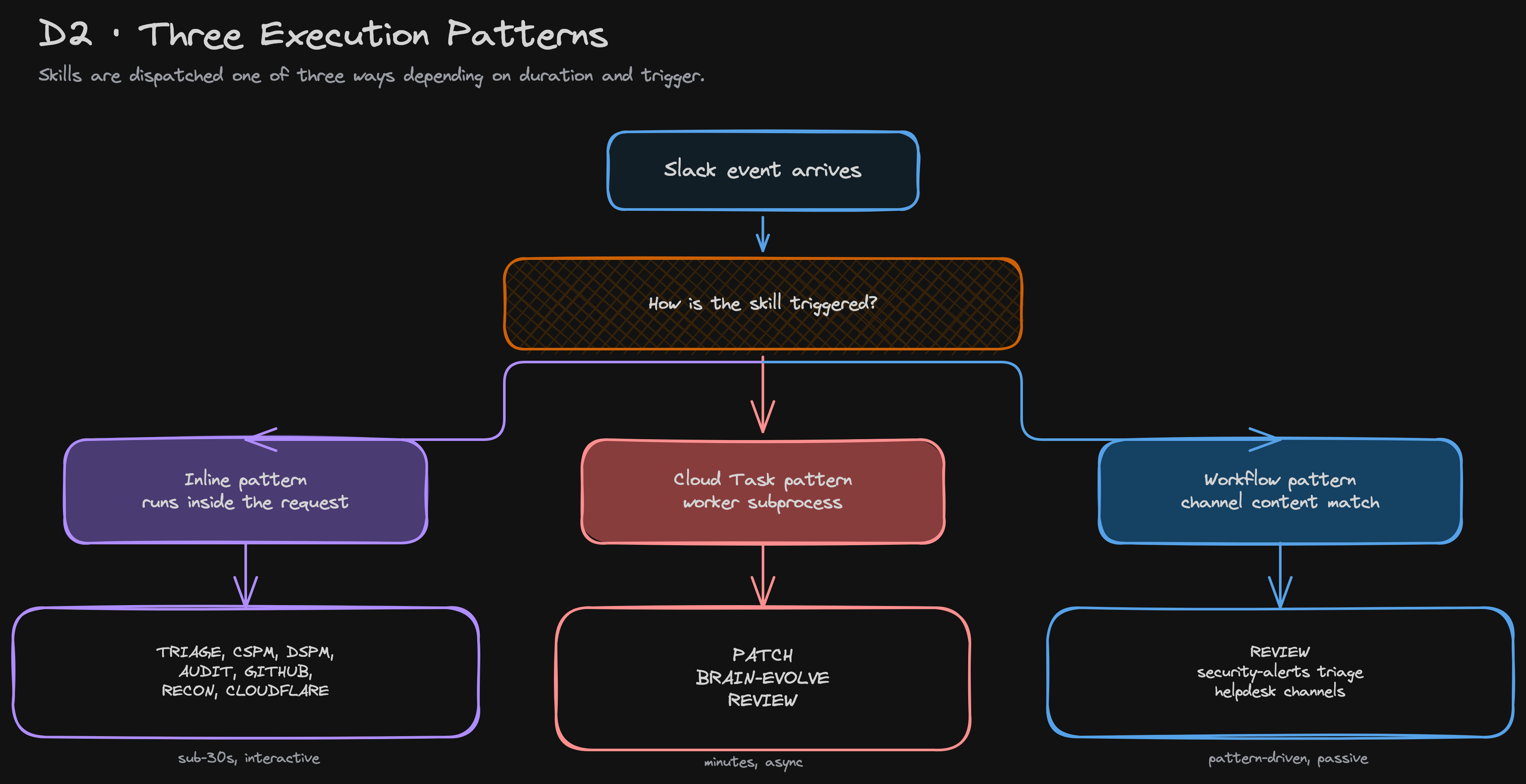
We picked three execution patterns for skills, based on duration and trigger:
- Inline:
triage,cspm,audit,github,recon,cloudflare,dspm. The tool runs inside the orchestrator's HTTP request. Fast (sub-30-second), interactive, can post buttons. - Cloud Task:
patch,brain-evolve. The orchestrator enqueues a task and posts a "queued" Slack message in under three seconds. The same Cloud Run image — different instance — then dispatches/worker/execute, runs the Claude Code CLI as a subprocess for several minutes, and updates the same Slack message in place when done. One image, two roles, isolated bymax_instance_request_concurrency = 1. Ten patch jobs that would take ~50 minutes sequentially finish in ~5 minutes across parallel instances. - Workflow:
review,security-alertstriage,helpdesk. The user never types a skill name. The Slack event handler detects a pattern — a PR URL, a bot-posted alert, a message in a helpdesk channel — and pins the agent loop to one skill with a narrowed tool surface.
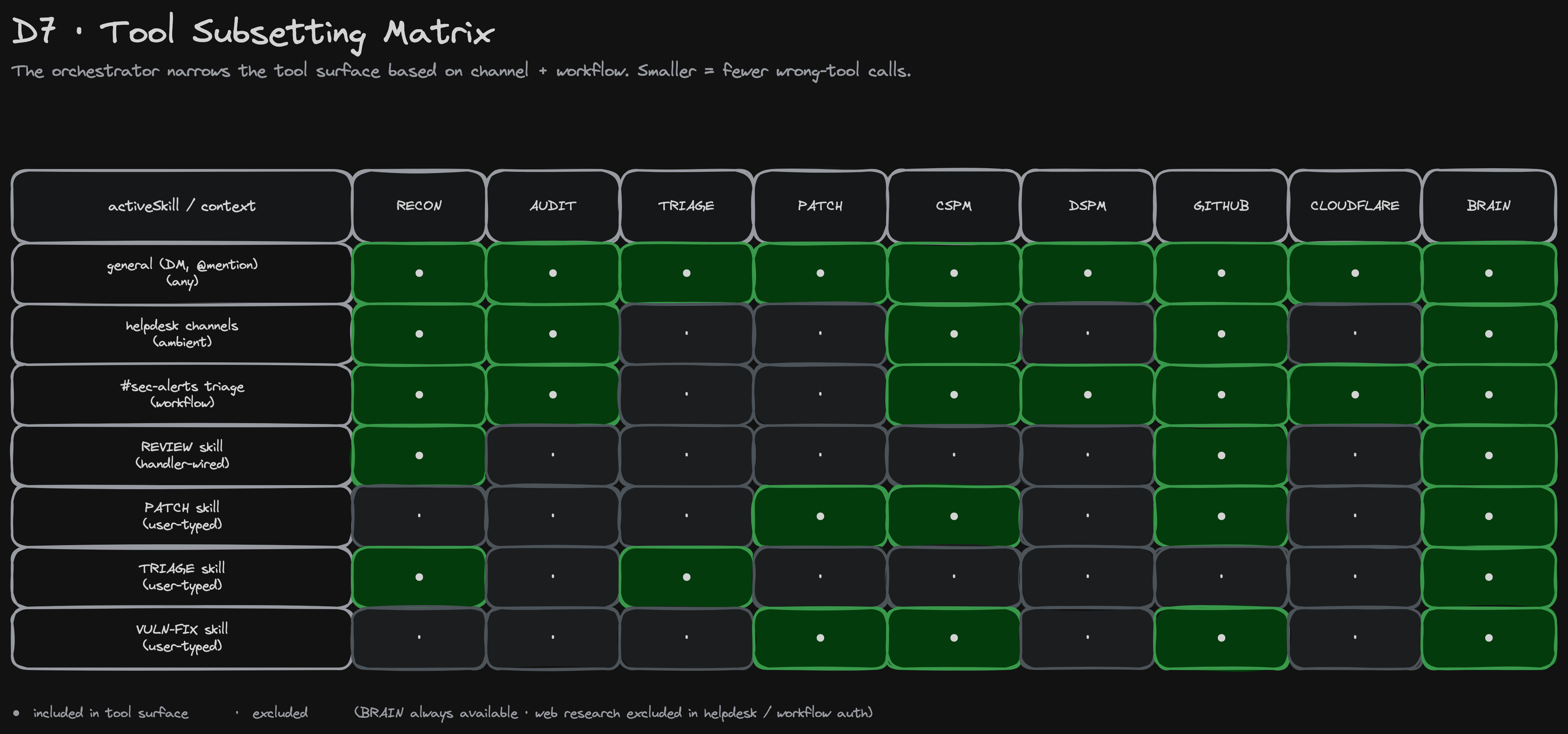
That last property — tool subsetting — turned out to matter more than we expected. Giving a model 56 tools to pick from on every turn produces worse decisions than giving it the eight tools relevant to the current channel and workflow. The catalog at src/agent/system-prompt/catalog.js is the single source of truth: 14 user skills, each declaring which tool names it owns and which auxiliary skills' tools it pulls in. When the agent is in #sec-alerts, it sees only CSPM + DSPM + Cloudflare + Brain + a few reads. When it's reviewing a PR, it sees only GitHub + Recon + Brain. Smaller surface, fewer wrong-tool calls, tighter authorization gates.
Testing alongside prod: Channel-aware routing
Two Cloud Run services from the same image, declared in YAML, fanned out via Pub/Sub
The platform runs two Cloud Run services from the same image: trm-security-agent (prod) and trm-security-agent-staging (staging). They share one Slack app, one Firestore database, one set of secrets, and a single Pub/Sub fanout. The thing that makes this safe is a single YAML file — agents-config.yaml — that declares which Slack channels each service owns.
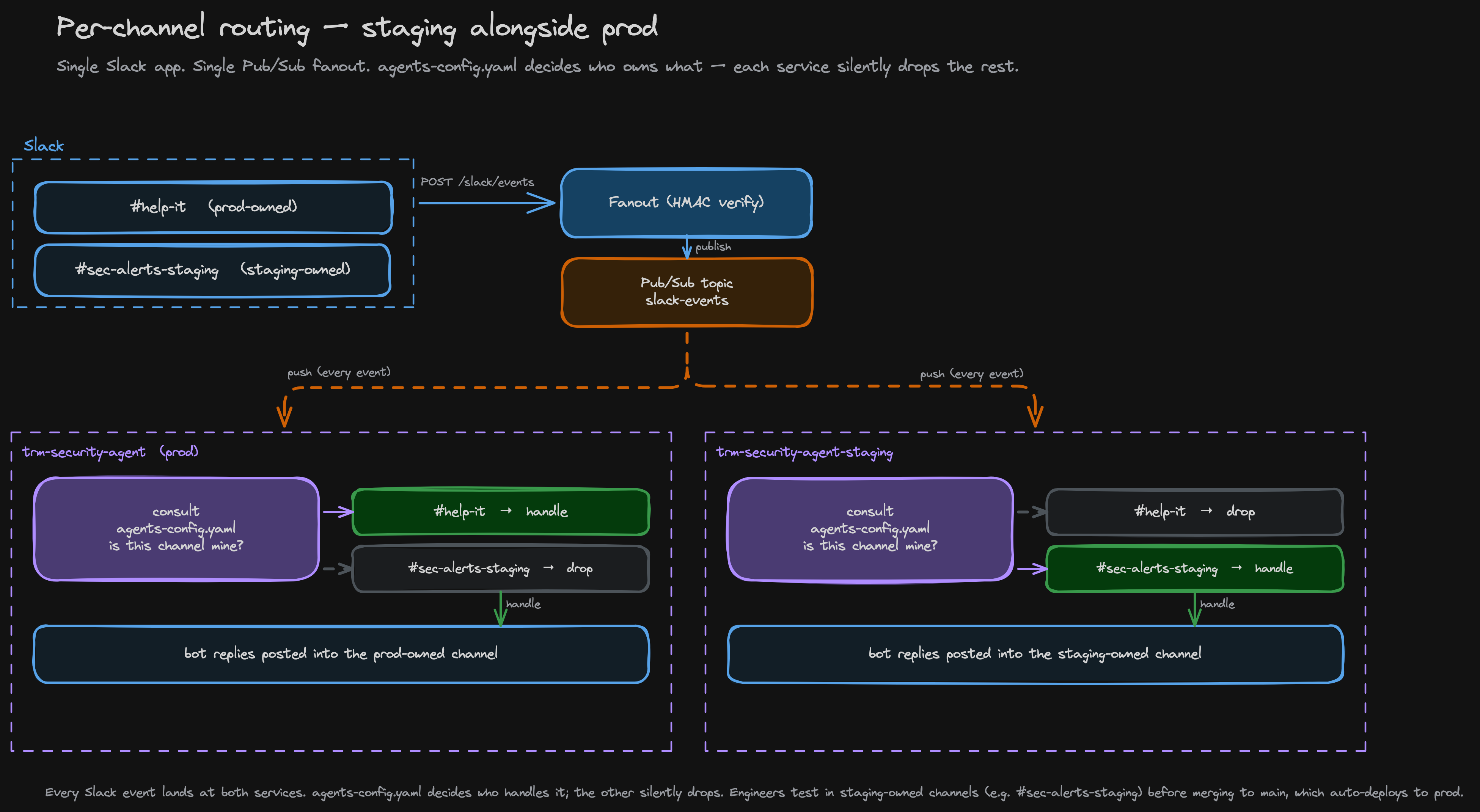
The fanout is the only thing Slack posts to. It verifies the HMAC signature once and republishes the event to a Pub/Sub topic; both Cloud Run services subscribe via push, so every Slack event lands at both. Each service then reads agents-config.yaml to decide whether the event's channel is one it owns. If not, the event is silently dropped: no log noise, no double-handling.
A stripped-down view of the config:
orchestrators:
prod:
cloud_run_service: trm-security-agent
workflows:
helpdesk:
- "#help-it"
security_alerts:
- "#sec-alerts"
review:
- "#eng-reviews"
- "#infra-reviews"
# … plus other engineering channels
mention_only:
- "#sec-questions"
enabled_skills:
- helpdesk
- patch
- triage
- cspm
- dspm
- vuln-fix
- audit
- github
- brain
- review
- self-review
- investigation
- recon
- cloudflare
- grc
- ...
staging:
cloud_run_service: trm-security-agent-staging
workflows:
helpdesk:
- "#help-it-staging"
- "#help-it-admin-staging"
security_alerts:
- "#sec-alerts-staging"
mention_only:
- "#pr-review-staging"
enabled_skills: [same shape as prod]The payoff: Engineers ship a feature to staging-owned channels, test against real Slack and real Firestore state, and only merge to main once they're happy, at which point a GitHub Action auto-deploys to prod. For per-branch isolated iteration (when two engineers need staging at the same time), the staging Cloud Run service can host multiple sibling revisions, each with its own routing entry in Firestore. The basic mechanism stays the same simple idea: a config file decides what gets handled where.
Autonomous triage of security alerts
What happens when a security alert fires, and when the agent gets to close it without asking
At TRM, security alerts generated from our telemetry stack are centralized in the #sec-alerts Slack channel, where engineers are responsible for triaging, investigating, and remediating potential security issues.
The clearest application of the orchestrator pattern is #sec-alerts. Every bot-posted message in that channel is a security alert from across our detection tooling. Each one used to be a tap on the on-call's shoulder. Now each one runs through Claude Opus before a human sees it.
The handler fires on any top-level message in the channel whose author is a bot. It builds the alert body, fences it against prompt injection, and runs the agent loop with an in-memory workflow identity of security-alerts. That workflow identity is the bot's passport: a scoped allowlist grants the agent ~25 tools: CSPM read + close, Recon, GitHub read, Cloudflare read, DSPM read, Brain, and a meta-signal called security_alert_resolve, without the agent ever pretending to be a human security-team member.
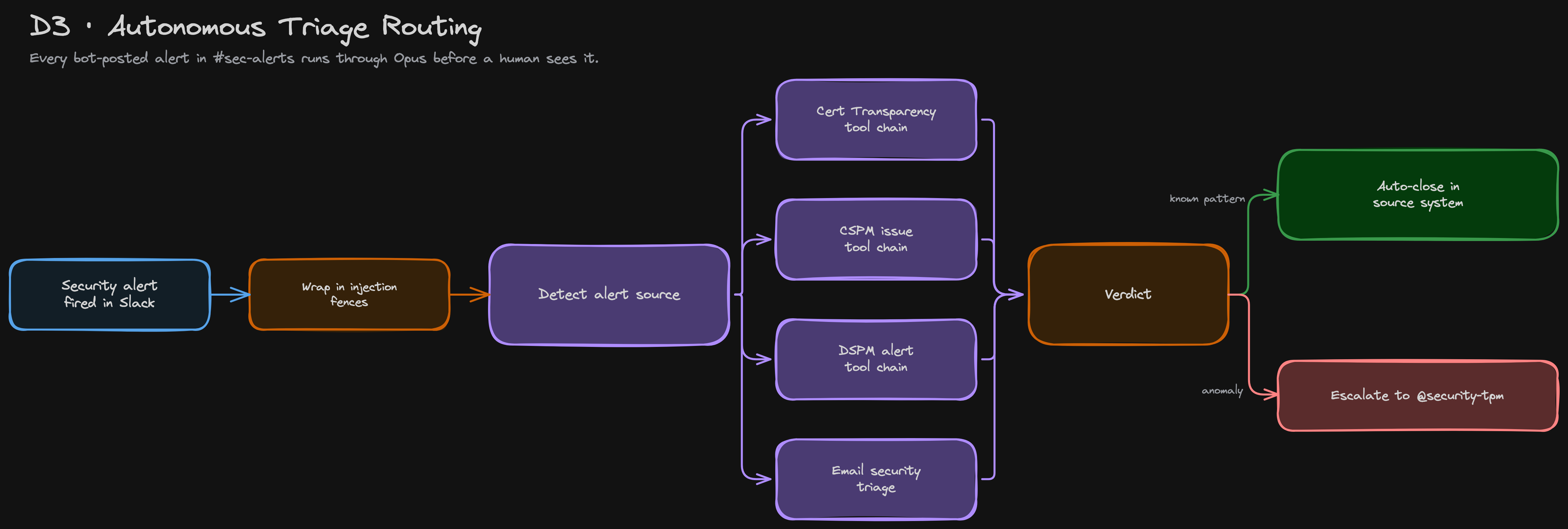
From there, triage resolves to one of three outcomes:
- The agent auto-closes well-understood, low-risk alerts at the source
- Enriches and flags the ones that need a human's judgment
- Escalates the rest with the context it already gathered attached.
The on-call's queue shrinks to the alerts that genuinely need a person. But auto-closing an alert is the lightest form of autonomy; the harder problem is letting the agent change code, which is exactly where this platform began.
Autonomous remediation: patch and vuln-fix
How the original CVE patch agent lives on as one skill among many, plus the multi-package PR bundling we built on top
patch is the direct descendant of our V1 vulnerability agent, but the reinforcement-learning loop is gone, replaced by something dramatically simpler. The two-stage shape survived intact: the agent first makes the code changes inside an isolated, sandboxed worker, then opens a pull request with the fix. What used to be a bespoke ML pipeline is now a general-purpose coding agent pointed at a narrow, well-scoped task: remediation the team can review and merge like any other PR.
The differences are where the platform shows up:
- Dedup check before every run. Before opening a new PR, the agent checks for in-flight or recently-completed patch tasks on the target repo. If one's already running, it links back to that Slack thread rather than racing. If the requested package was already patched, it returns the existing PR URL. The model never wastes a turn on duplicate work.
- Smart version selection prompt that reads the lock file first (no-op if already patched), then picks the best version ≥ the scanner-recommended minimum, preferring the latest patch in the same minor, never crossing a major. Supports npm, yarn, pnpm, pip, poetry, uv, go mod, Maven, RubyGems with targeted lock regeneration.
- WebFetch grounding against an allowlist of NVD, OSV, npm, PyPI, GitHub advisories, and vendor PSIRTs. Fetched content is treated as untrusted data; URLs are cited in a Sources section in the PR.
- Safety hooks that block force-push, hard reset, rebase,
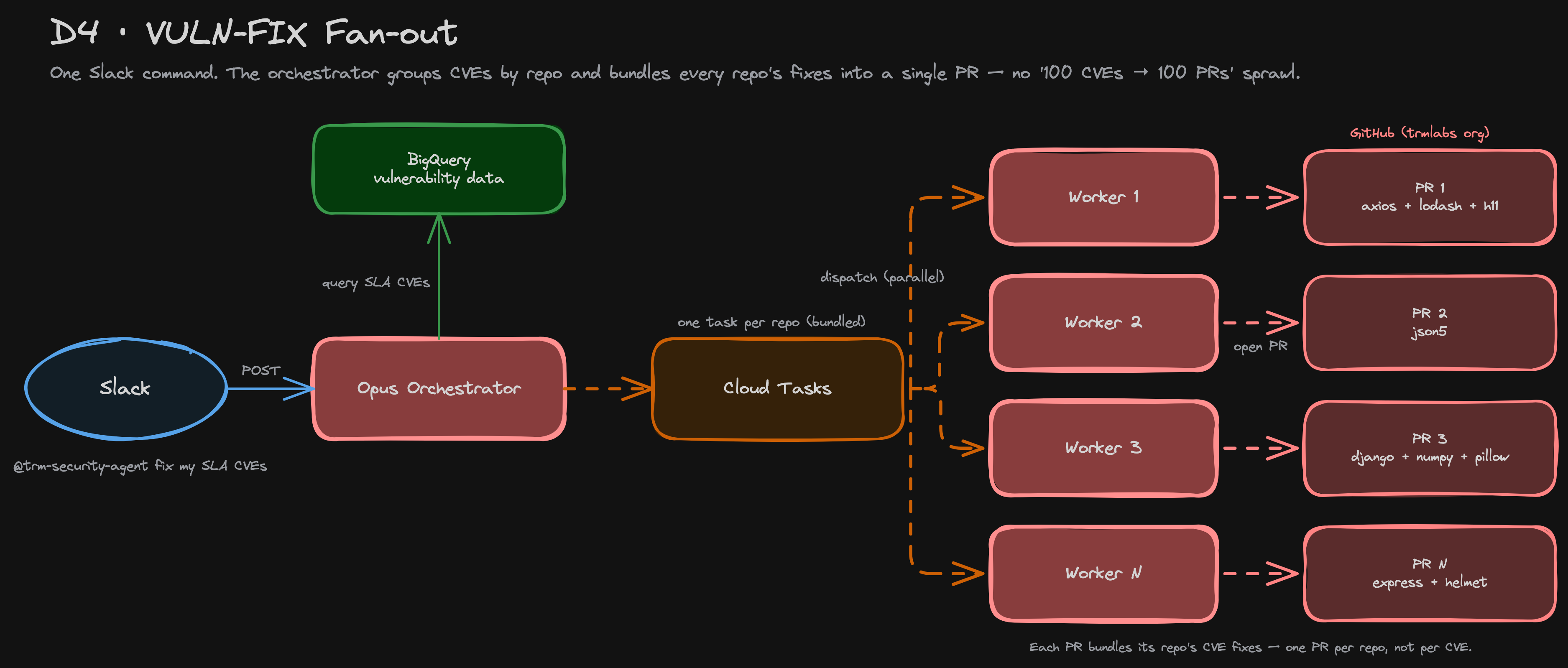
rm -rfoutside/tmp, secret dumps, SQL DROP — before they execute in the subprocess. - Bundled PRs. When more than one package needs patching in a repo, one Claude Opus run produces one PR. The "100 CVEs → 100 PRs" sprawl from the early days is closed.
- Interactive amendments (
patch_amend_pr). The reviewer can say "bump h11 down to 0.15.2 instead" or "remove all the highs from this PR" mid-thread; the bot pushes new commits to the same branch via a shorter amend subprocess (10-min budget vs 30 for fresh patches).
The vuln-fix skill is the bulk entry point. @trm-security-agent fix my SLA CVEs queries BigQuery (the SLA-CVE table that backs the Looker dashboard), groups by repo, dedupes packages, skips anything with an in-flight task, and enqueues one patch job per repo. With Cloud Run scaling out to ten parallel instances, a single Slack command can fan out across a team's open vulnerabilities in parallel.
Autonomous PR review (with agent approval)
Regex → Haiku → cache → Opus: How every infrastructure PR gets reviewed in seconds, and when the agent is allowed to click approve itself
The review skill is what makes the system feel autonomous to people outside the security team. When anyone posts a TRM infra-related PR URL in a channel the bot owns, the bot reviews it.
The pipeline is built for cost as much as quality. Each Slack message goes through a regex match first (essentially free); if it hits, a Haiku intent classifier decides in ~200ms whether the message is actually asking for review (PTAL, lgtm?) or just chatter (merged, FYI, link in passing). Only on intent-match do we hit the Firestore verdict cache, keyed by ${repo}-${pr}-${headSha}; new commits force a fresh review automatically.
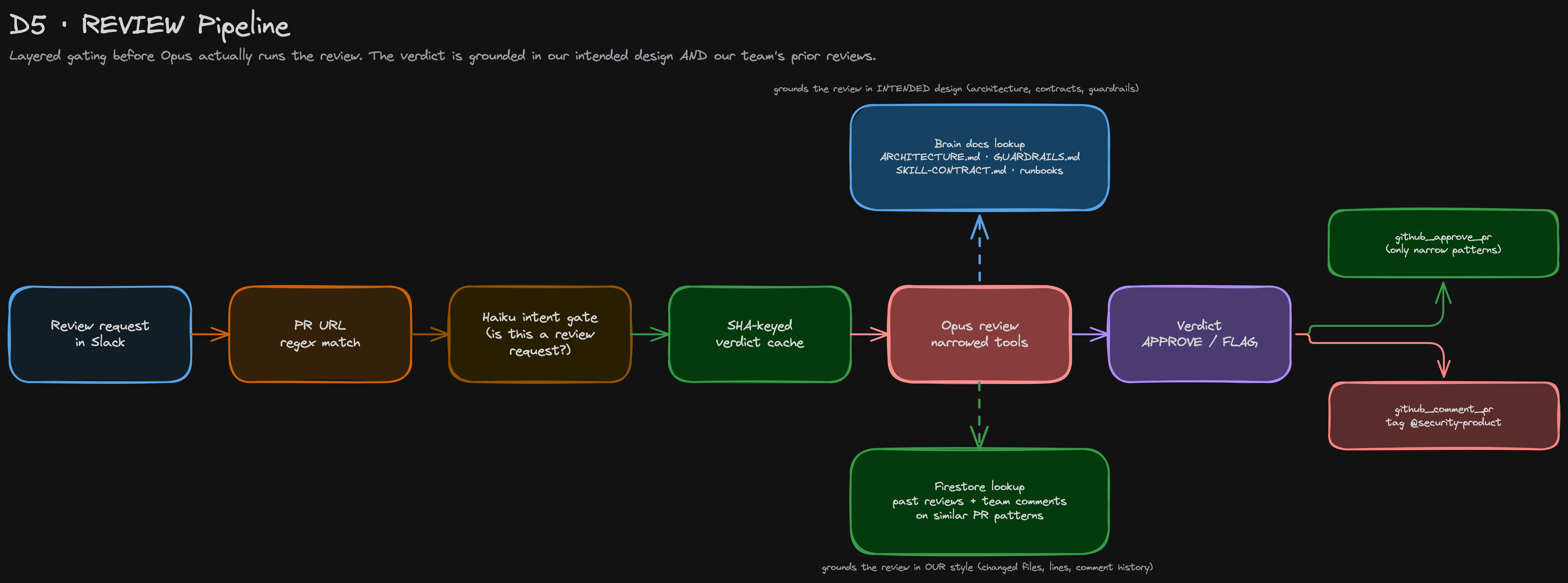
The model emits a structured verdict — APPROVE, FLAG, or ABSTAIN — with reasoning. For a small, well-understood set of low-risk patterns (additive read-only IAM on non-prod, single-line egress allowlist additions, additive activate_apis, terraform fmt-only diffs), the bot calls github_approve_pr as the trm-security-agent GitHub user. Not a bot account; a real user with a PAT, so CODEOWNERS rules listing @trm-security-agent are satisfied. For anything outside that list — org-level IAM, deletions, owner roles, anything touching prod — it calls github_comment_pr with a categorized findings post and tags @security-product. Every action is mirrored to the Slack thread. Agent approvals are never silent.
At current PR volume, review runs around USD 5–12 a day in model spend. More importantly, it unblocks engineers at near-instant speed on the well-structured, low-risk PRs that would otherwise sit awaiting a human reviewer.
The institutional-memory flywheel
Every live triage produces a knowledge observation; every observation becomes a doc PR; every merged doc PR sharpens the next triage
The agent's knowledge base is a curated corpus of internal documentation: runbooks, SOPs, IR playbooks, end-user guides, plus the SCF control catalog. It's indexed in memory at startup and exposed to every skill through a search interface.
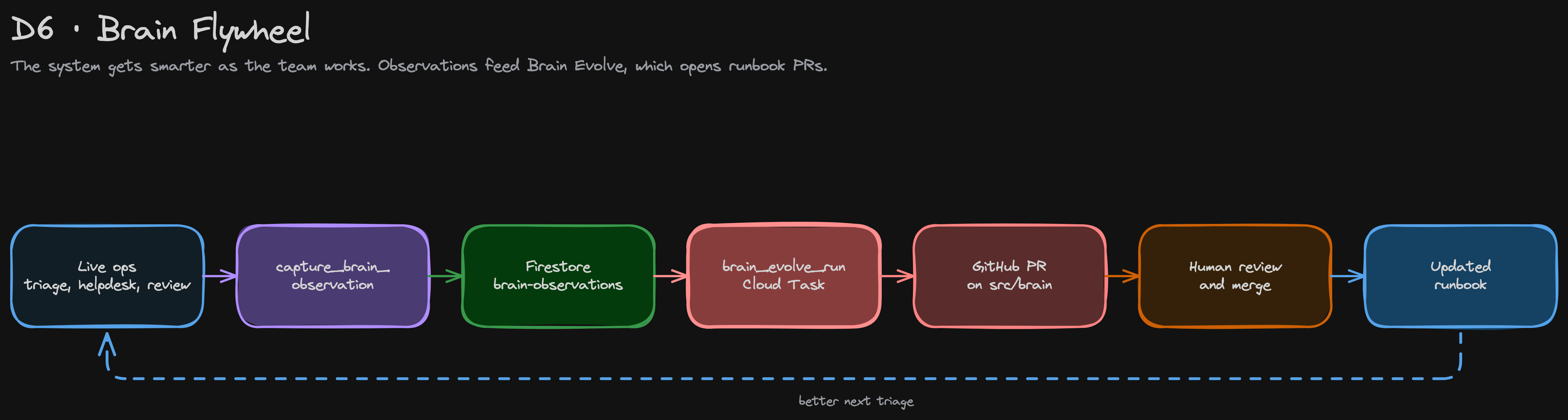
What makes it interesting is the closed loop. During every triage, every helpdesk reply, every PR review, a parallel tool called capture_brain_observation lets the agent silently record "this would have gone faster with a runbook on X." Observations land in Firestore, rate-limited per category. When a security-team member triggers brain_evolve_run, a Cloud Task reads stale observations (>24h old), drafts new or improved runbooks via Claude Opus, and opens PRs against src/brain/. Every brain-evolve PR still passes through human review. The flywheel isn't only passive. Engineers also drive it directly — phrases like "add this improvement to your todo list for the IR workflow" capture targeted observations on demand, and "show me your todo list" surfaces them grouped by workflow. The brain doubles as a shared scratchpad the team and the agent both contribute to.
The system gets smarter as the team works.
Where humans still gate
The decisions we explicitly keep out of the agent's hands
The platform is autonomous, not reckless. Every irreversible action passes through a deliberate human gate.
- High-blast-radius operations: Anything irreversible follows a Block Kit risk-report flow. The agent analyzes the context up-front, posts a risk report with Proceed / Cancel buttons, and waits for a human click before executing. Claude is never in the confirmation loop. Slack interactivity is.
patchworkers create PRs autonomously, but never merge them. CODEOWNERS still applies.reviewapproves only for the narrow patterns above; anything ambiguous goes to FLAG, which routes to@security-product.brain-evolvePRs are reviewed before merge.
Auto-merge on green CI for the narrowest repeated patterns — the obvious next step — is on the H2 2026 roadmap. Today, every code-changing PR still ends with a human clicking Merge.
The outcome: Running it like a production service
Why we stopped reporting one-workflow metrics and started publishing per-workflow SLAs against a unified telemetry pipeline
The reframe: From "remediation rate" to "production SLAs"
In V1, we measured a single workflow — patch — against an MTTR target and an auto-remediation rate. Now that the agent runs many workflows continuously, the metrics that matter are the ones you'd publish for any production internal service: throughput, success rate, latency, error rate, and user feedback, per workflow, against an SLA.
What our V2 architecture enables that V1 couldn't:
- A per-workflow operational dashboard the team actually uses every day (
helpdesk/security-alertstriage /review), not just at blog time. - A persistent 180-day record of every workflow interaction we can query at any time for ad-hoc analysis.
- A standardized GenAI metrics surface powered by Groundcover's AI Observability plus the public OTel GenAI semantic conventions, covered in the next section.
Production system in operation — last 30 days

Top-line: ~10,000 interactions across all workflows in the past 30 days. ~51,000 LLM calls instrumented end-to-end.
helpdesk's "45% resolved without a ticket" is the strict bar. Every other interaction still does real work: the bot pre-populates a Zendesk ticket with the full Slack thread, so the on-call doesn't rebuild context from scratch when they take over. The assisted-resolution rate is meaningfully higher than the strict one.
security-alerts triage is the cleanest auto-resolution story so far. ~238 alerts (17%) closed without paging anyone; the rest escalated cleanly with enriched context attached.
review is the newest workflow on this dashboard and the fastest-growing — every infrastructure PR URL posted in a bot-owned channel goes through the regex → Haiku → cache → Opus pipeline before a human gets pinged.
Evolving from V1: The observability rebuild
V1 used a homegrown telemetry path: custom counters in our app database, manually maintained dashboards, separate code for pulling platform metrics. It worked for one workflow, but got painful immediately when we needed to compare five.
The new stack came together in two deliberate upgrades:
1. OpenTelemetry GenAI semantic conventions
Every model call (orchestrator turns, classifiers, worker subprocesses) emits the spec-defined histograms for call duration, token usage by type, and tool calls per operation. Because it's the public spec, the data is portable: any GenAI-aware backend can light up against our deployment without re-instrumentation.
2. Groundcover AI Observability as the backend
We export the OTel data via OTLP, and the LLM Performance and Tool Performance rows in the diagram above light up the same day: per-agent latency, prompt-cache hit ratio, token-type mix, p95 duration and error rate across all 56 instrumented tools. The picture we get is the shape of our AI traffic without ever shipping prompt or response bodies to a third-party vendor, important for a security tool whose prompts can include alert content.
SRE for an AI agent
Treating trm-security-agent as a production service — not a clever automation script — is what made multi-workflow scale possible. Once we committed to per-workflow service-level targets, every subsequent decision got cleaner. New skills inherit the same instrumentation by virtue of routing through the same orchestrator. New workflows publish a target before they ship and prove it before they call themselves done. Regressions show up as a number on a dashboard instead of as a complaint in #incident-response.
Applying SRE principles to an AI agent is the only way we've found to scale this sustainably. Latency targets, error budgets, and explicit user-visible service levels let us layer helpdesk and review on top of the original patch workflow without losing visibility into whether any of them were quietly getting worse. The same orchestrator-workers pattern that lets one model dispatch to many skills also gave us one telemetry pipeline that covers all of them.
What's next
Three things on deck for the next cycle
This post focused on the architecture and the autonomy story because that's what made everything else possible. The interesting follow-ups are how the same platform unlocks workflows that have nothing to do with vulnerability management.
Three deep-dives are coming in this series:
- Enterprise security and IT support: How we replaced ClearFeed with a Slack-native helpdesk built on top of this same agent. End-to-end Zendesk integration, per-user enterprise-search OAuth, image attachment handling, brain-first runbook search, and a 3-button outcome prompt that lets users mark issues resolved without ever leaving the thread.
- Incident response: How we turned the security agent into the on-call security responder, from page to resolution to post-mortem. Channel auto-creation, structured intake, status broadcasts, IC and Comms lead coordination.
- GRC: How the same agent automates continuous compliance and evidence collection across FedRAMP High and SOC 2 audits, using the SCF control catalog as a structured backbone.
The thread tying all three together is the one we covered here: an orchestrator that meets engineers in Slack, holds 14 skills behind a single interface, and is allowed to act — carefully — when the next step is unambiguous.
If you're building an autonomous security agent, start here
- Pick one repeatable shape: Find the five-step pattern under your security workflows and design for it.
- Treat your existing chat tool as the UI: Don't ship a new console; meet engineers where they are.
- Narrow the toolbelt per workflow: Subset tools by channel and context before scaling skill count.
- Scope autonomy tightly: Let the agent approve only well-understood, low-risk patterns; escalate everything else with enriched context.
- Instrument from day one: Per-workflow SLAs and one shared telemetry surface unlock the multi-workflow scale story later.
{{horizontal-line}}
Join our team
The TRM Security Agent is part of TRM Labs' broader AI-driven infrastructure initiative. Our engineers are building AI-powered autonomous agents that protect civilization from evolving cyber threats. We're scaling security across 150+ repositories, processing petabytes of blockchain data, and building the future of autonomous security operations to fight crime and build a safer world.
Think you can build better AI agents than the ones we have today? Explore opportunities and apply: https://www.trmlabs.com/careers







