10 min
How TRM Handles Blockchain Reorgs Across EVM Chains
Blockchain reorganizations can silently corrupt data pipelines by shifting transactions, logs, and execution outcomes. This post explains how TRM detects, corrects, and reconciles reorgs across real-time systems.
Blockchain reorganizations are one of the hardest problems to solve in blockchain data engineering.
A reorg occurs when a network replaces one or more recently accepted blocks with an alternative chain. From a data pipelines perspective, that means data you have already ingested may suddenly become stale. Transactions can move to different positions, internal call trees can change, log indices can shift, and in some cases a transaction that succeeded in one version of the chain can revert in another.
Reorgs present a data correctness problem that propagates through every downstream table built on top of affected blocks.
At TRM, we process blockchain data across many Ethereum Virtual Machine (EVM)-compatible chains in both real-time and batch systems. Every one of those chains can experience reorgs. This post walks through how reorgs corrupt data, why they are harder to fix than they first appear, and the multi-layered strategy we built to handle them.
Key takeaways
- Reorgs can change transaction position, log indices, trace trees, timestamps, and even execution outcomes. The problem goes well beyond duplicate data.
- Waiting for finality avoids reorgs, but adds too much latency for real-time products. For TRM’s use cases, that tradeoff is not acceptable.
- Reorg handling requires multiple layers. Detection, republishing, per-table deduplication, and cross-table reconciliation all matter.
- The transactions table acts as the canonical source of truth. Anchoring downstream tables to canonical transaction timestamps is what restores consistency after a reorg.
What happens during a reorg
Under proof-of-work, reorgs happen when two miners find valid blocks at nearly the same height, creating a temporary fork that resolves when one chain grows longer. Under proof-of-stake (Ethereum post-Merge), each slot has a single designated block proposer, but reorgs still occur, typically when a proposer’s block arrives late due to network latency and attesters vote for a different chain head, or during brief network partitions. In both cases, the blocks on the losing fork are “reorged out,” and their transactions may or may not appear in the winning chain.
From a data pipeline’s perspective, the damage depends on how far along you were in processing the old blocks before the reorg happened.
The easy solution: Just wait
The simplest way to avoid reorg problems is to delay ingestion until blocks are finalized.
On Ethereum post-Merge, finality is typically on the order of 12–15 minutes. If a pipeline waits until then, it will only process blocks after the network has settled on the canonical chain.
That approach works well for analytics systems where a delay is acceptable. But for TRM’s products, where compliance teams need to assess transaction risk in near real time, waiting that long is not an option. Some chains also have longer or less predictable finality windows.
Instead, we process blocks as soon as they are produced and accept that some will later be reorged. This means we need a system that can detect reorgs, correct the data, and clean up whatever was already written downstream.
The data you already ingested doesn’t go away
Most blockchain data pipelines work by streaming block data in near real time and writing it to a database. When a reorg occurs, the pipeline has already published the old block’s data downstream, and consumers have already written it to storage. The old data persists alongside the canonical replacement, creating duplicates. But the damage goes beyond simple duplication.
Beyond duplicates: Shifted indices
A common first instinct is “deduplicate on transaction hash.” But reorgs don’t just duplicate data, they shift it. Consider a transaction 0xBB that was at position 1 in the old block but ends up at position 5 in the canonical block:
- The
log_indexfor every event changes (0, 1 → 5, 6) - The
trace_idandtrace_addressfor every internal call change - The
block_timestampchanges (different block, different time) - The
block_numbermight change (if the tx lands in a different block entirely)
If your deduplication key includes log_index or trace_id (as ours did), the old and new rows look like completely different records. Both survive the dedup, and you end up with double the data.
The main reorg failure modes we saw
Over the course of building and operating our pipeline across all chains, we catalogued multiple ways a reorg can corrupt data. Some are obvious, others took production incidents to discover.
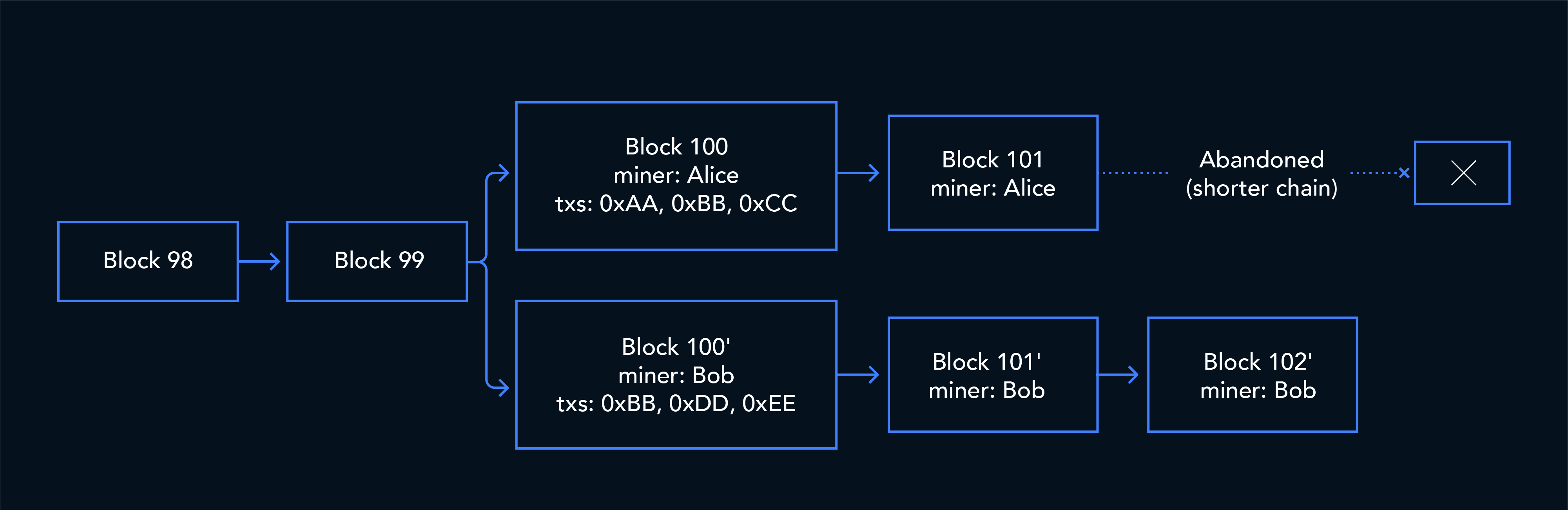
1. Same content, shifted positions
This is the simplest case.
The transaction executes identically in both versions of the chain, producing the same traces or token transfers, but at different positions. The semantic content is unchanged. Only positional metadata moves.
A positional deduplication strategy sees different (transaction_hash, log_index) pairs and keeps both rows. A semantic deduplication strategy collapses them correctly.

2. Different execution, different content
The EVM is state-dependent.
When a transaction lands in a different block, it can execute against a different pre-state because the transactions before it are no longer the same. That can change the entire execution tree: a sub-call that succeeded before might now revert; logs may disappear; token transfers may no longer exist.
This means the same transaction hash can legitimately produce a different set of traces and transfers across the two forks.
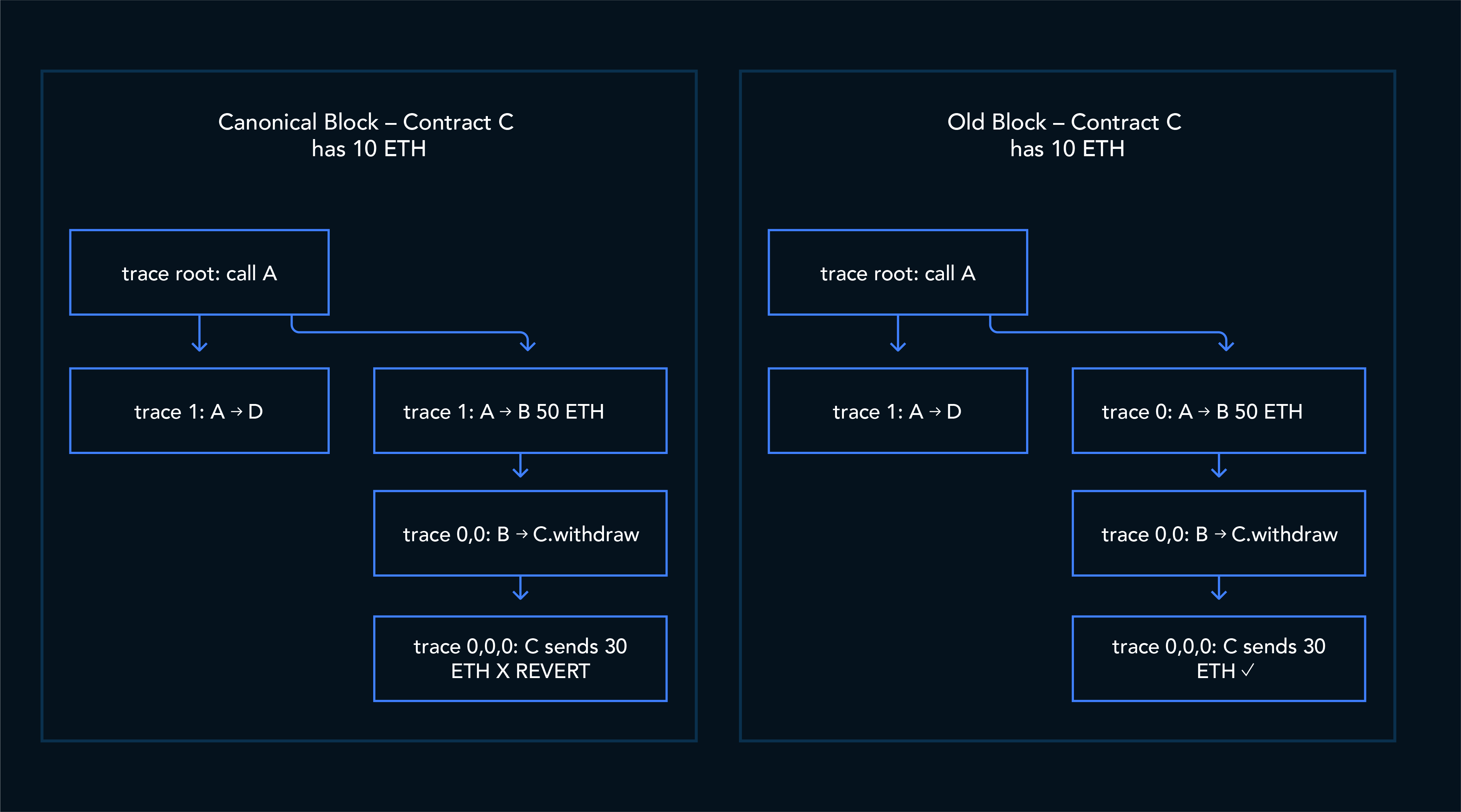
Same transaction hash, but the trace at [0,0,0] succeeds in one block and reverts in the other. The logs emitted by that sub-call (and any token transfers derived from them) exist in the old block but are absent from the canonical one.
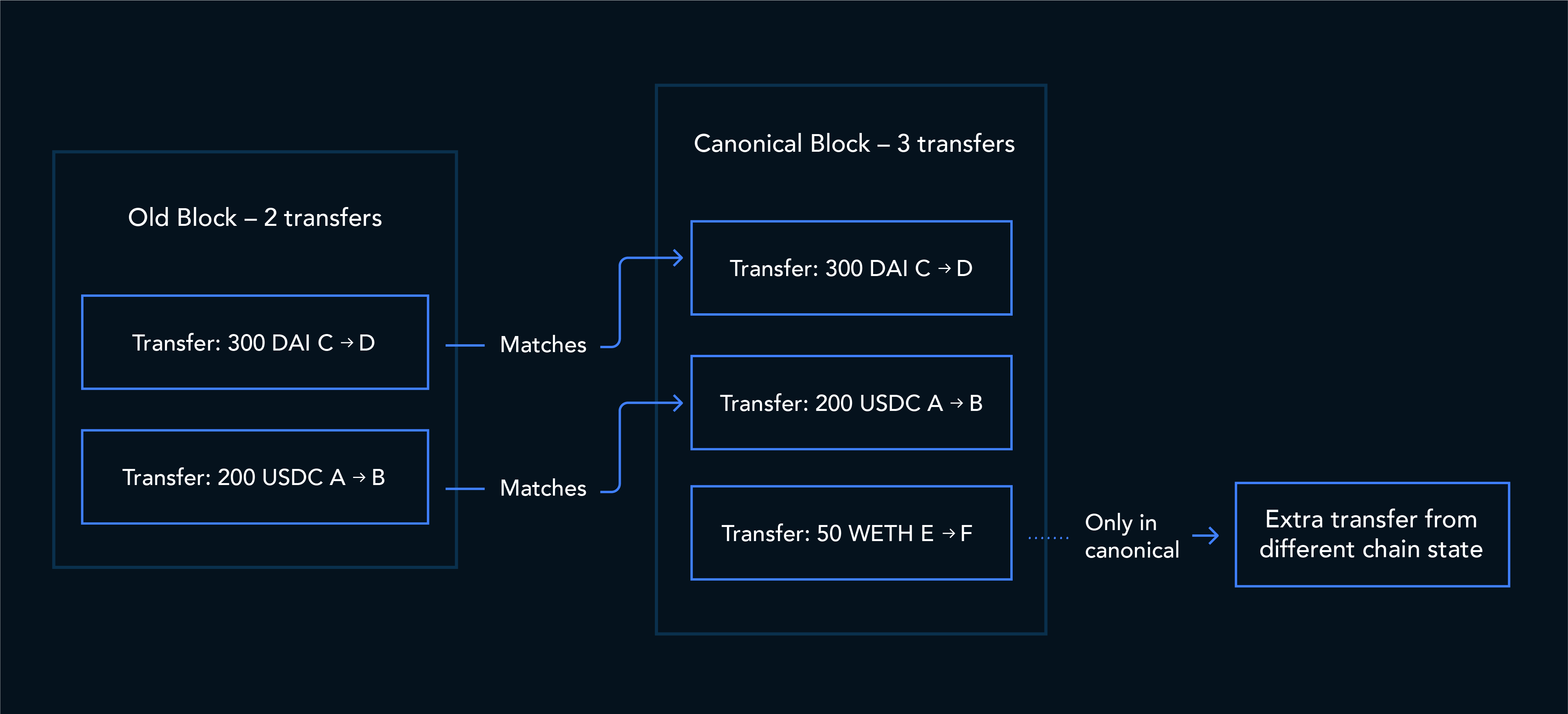
3. Different transfer counts
A related case is when the number of emitted transfers changes between forks.
For example, a router transaction might produce two token transfers on the old fork and three on the canonical fork because pool state changed. Semantic deduplication can resolve rows that still match between the two executions, but rows that exist only on one side remain.
The result is a single transaction hash with records tied to different timestamps and different semantic outputs, which breaks downstream joins and consistency assumptions.
4. Table-level inconsistency across RPC calls
This is one of the less obvious failure modes.
Our pipeline fetches blocks, receipts, and traces through separate remote procedure call (RPC) requests such as:
eth_getBlockByNumbereth_getBlockReceiptstrace_block
Those requests can be routed to different nodes behind a provider’s load balancer. If a reorg happens between calls, one response can come from the old fork while another comes from the canonical fork.
That creates cross-entity inconsistency: blocks may reflect the canonical chain while receipts still reflect the old fork.
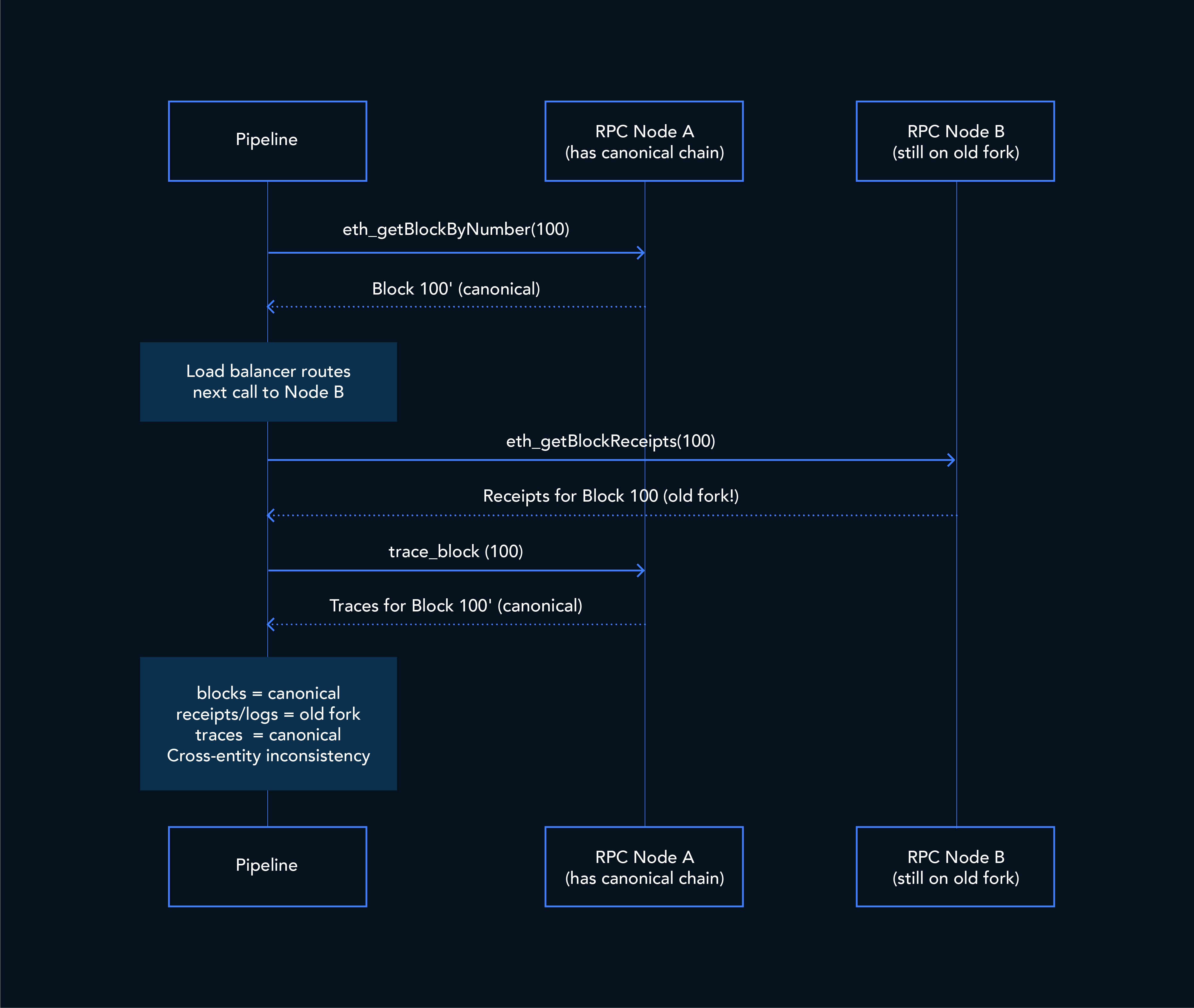
To catch this, we compare block hashes across all fetched entities and retry the batch if they do not agree.
But even after per-table deduplication, we still need one more step: force every table to agree on the same canonical transaction version.
5. Pure duplicates from republishing
Some reorg scenarios create near-identical duplicates.
If the fixer (explained in the next section) republishes a canonical block and a transaction appears in both the old and new versions at the same position, then the resulting rows can have:
- The same transaction hash
- The same log index
- The same semantic content
- But different block timestamps
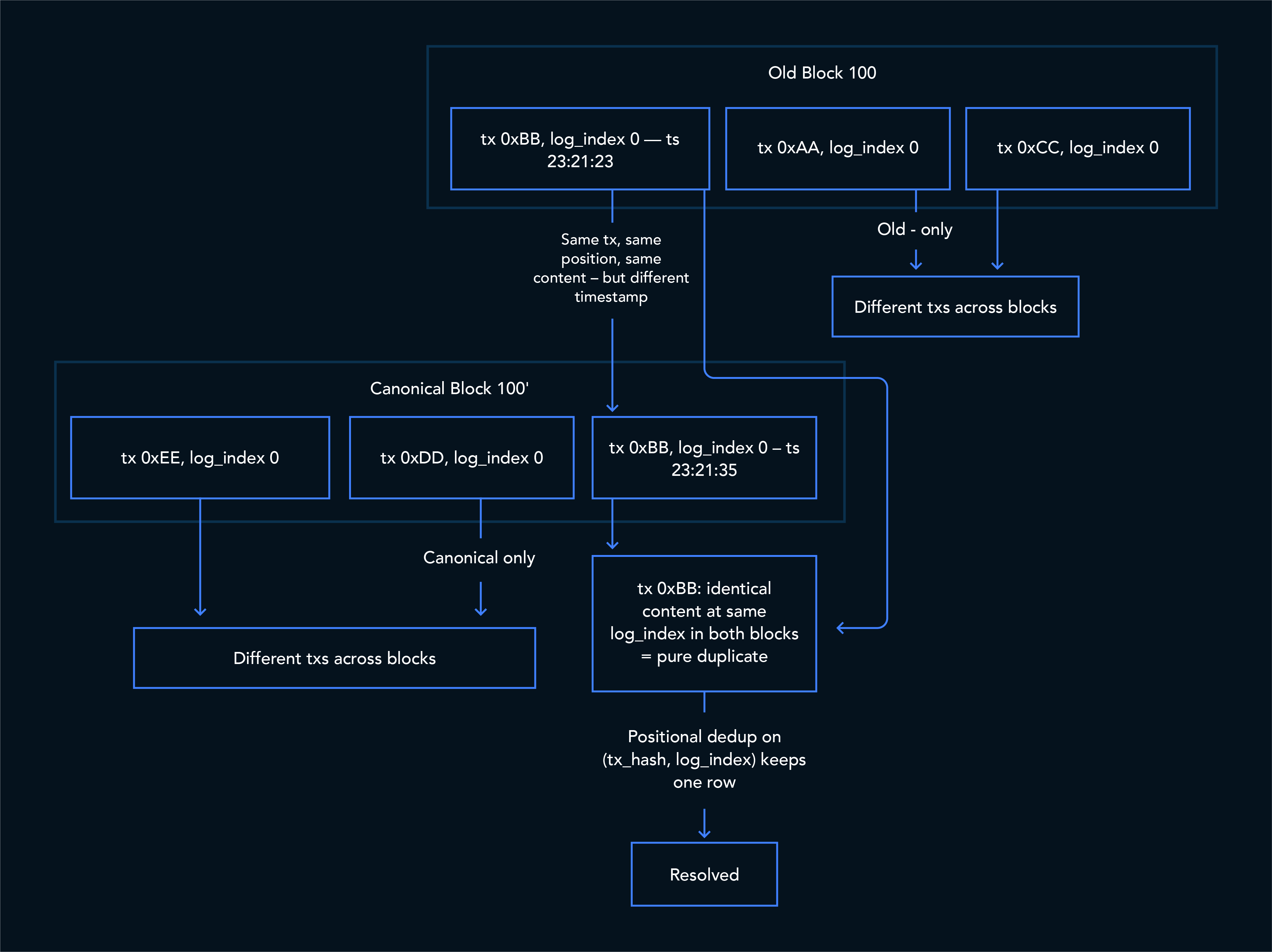
These are the easiest duplicates to resolve. The transaction landed at the same position in both blocks, so the content and log_index are identical — the timestamps differ but that's expected. The positional dedupe on (transaction_hash, log_index) for token transfers for example, keeps the row with the latest timestamp.
How we detect reorgs in real time
Our streaming pipeline maintains a local cache of recent block hashes. For each consecutive pair of blocks, it compares:
- The parent_hash of block N
- The hash of block N-1
If they do not match, block N-1 was reorged out.
Block 101: parent_hash = 0xABC
Block 100: hash = 0xDEF ← mismatch! Block 100 was reorged
When we detect a mismatch, a fixer re-fetches the block, which now returns the canonical version, and republishes it downstream. The cache is updated and the scan can continue downward to detect multi-block reorgs.
This mechanism is chain-agnostic. We originally built it for EVM chains and later extended the same idea to unspent transaction output (UTXO) systems.
How we deduplicate downstream
Detection and republishing solve the “get correct data out” problem, but the database still has both old and new data. That’s where the deduplication pipeline comes in.
Step 1: Detect reorged transaction hashes
Cross-reference the target table (traces, token_transfers, or logs) with the transactions table to find transaction hashes that appear with multiple distinct block_timestamp values.
Step 2: Semantic deduplication (reorged rows only)
For transactions flagged as reorged, deduplicate using “semantic” columns that describe the content of each row rather than its position. This might remove more rows than needed, but that’s an accepted tradeoff that would be corrected in the batch run anyway.
Step 3: Positional deduplication (all rows)
After the semantic pass, deduplicate on positional columns (transaction_hash + log_index for logs, transaction_hash + trace_id for traces) across the full result. This catches any remaining actual duplicates, for example, exact row-level duplicates from the republish scenario.
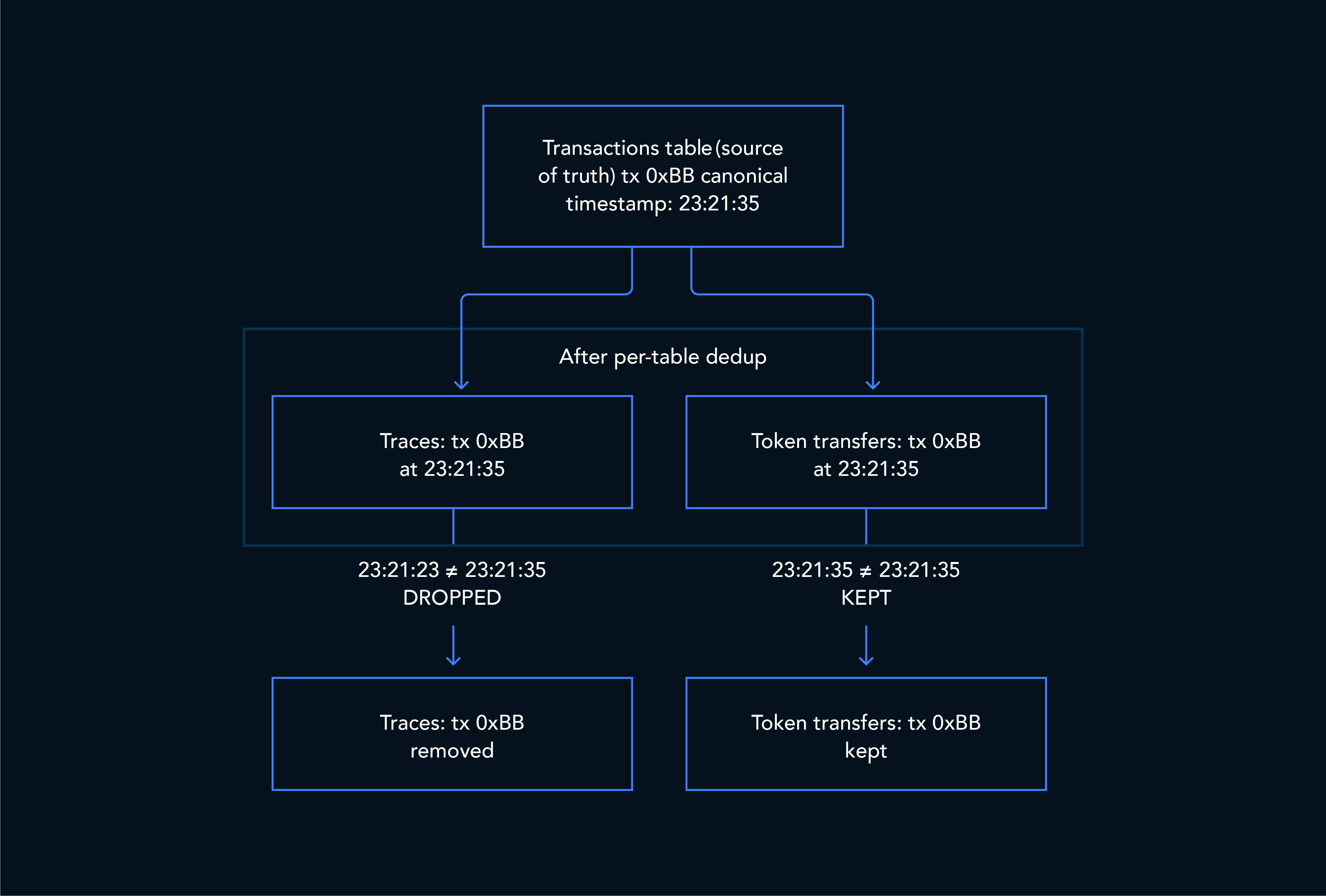
Step 4: Cross-table consistency via the transactions table
The transactions table, already deduplicated on hash, serves as the source of truth for which timestamp is canonical. In the database, a LEFT JOIN matches each row’s timestamp against the canonical one. Rows are kept if:
- The transaction doesn’t exist in the transactions table yet (safe fallback for delayed loads)
- The timestamp matches the canonical one
Rows are dropped only when we know the canonical timestamp and the row’s timestamp doesn’t match. This ensures traces, token_transfers, and logs all reflect the same block’s data when joined downstream.
Why the transactions table is the anchor
Reorgs are a fact of life on both proof-of-work and proof-of-stake systems. Handling them requires multiple coordinated steps:
- Real-time detection in the ingestion layer
- Correction through canonical republishing
- Downstream deduplication that accounts for both semantic and positional differences
- Cross-table reconciliation against a canonical source of truth
At TRM, that source of truth is the transactions table. That design lets us process blocks in near real time while still repairing the downstream effects of chain reorganization.
TRM Labs provides blockchain intelligence to detect and prevent financial crime. Our data pipelines process billions of transactions across more than 100 blockchains. If this kind of work interests you, we’re hiring.







